
PyNVMe3 Script Development Guide
Last Modified: February 19, 2025
Copyright © 2020-2025 GENG YUN Technology Pte. Ltd.
All Rights Reserved.
- 1. Test platform
- 2. pytest
- 3. Visual Studio Code (VSCode)
- 4. Basic script
- 5. Buffer
- 6. Pcie
- 7. Controller
- 8. Namespace
- 9. Qpair
- 10. Subsystem
- 11. IOWorker
- 12. metamode IO
- 13. SRIOV Testing
- 14. Desktop Test Platform
- 15. Summary
Whether on a PC or a server in the data center, storage is a core component as important as computing and networking. Computing component usually refers to the CPU, the network component usually refers to the network interface card. At present, the most popular storage component is NVMe SSD. While more and more manufacturers enter this market, the products of different manufacturers and even different products of the same manufacturer have different quality.
SSDs need to have full functionality, excellent performance, and high reliability. Client SSDs for PC also need to have good compatibility and low power consumption. Whether it is a start-up company that has just started 3-5 years, or an mature company that has been in the industry for more than 10 years, it is not easy to make an excellent SSD constantly. Especially from the point of view of data reliability, the quality of SSD is particularly important. After all, the network can be reconnected if it is down, and the packet can be resent if it is lost; If the CPU is broken, it can be replaced between Intel and AMD, x86 and ARM. But if your data is unluckily lost, it could not be recovered. There are so many manufacturers and products in the market, if you choose a poor quality SSD causing data loss, it is too late to change the SSD.
At present, many manufacturers rely heavily on traditional test tools such as fio/nvme-cli/dnvme and other commercial tools when testing NVMe SSDs. These tools can do some functional testing, but their performance does not meet the fast increasing NVMe/PCIe specifications. If the tool’s performance is low, the test stress would be low too, and some defects would not be detected. In addition, these tools are not friendly to the second development of test scripts, so they and cannot meet the requirements of rapid test case development in different scenarios. We have decades of SSD firmware development experience, and after suffering all kinds of pain and lessons from test tools, we decided to make a flexible NVMe SSD test tool by ourselves. Our purpose is to help manufacturers fully test SSD and help customers wisely choose right SSD.
This is PyNVMe3. After more than 5 years of development and promotion, PyNVMe3, as a third-party independent test tool, has been adopted by many worldwide SSD manufacturers and customers. Vendors are also increasingly interested in using PyNVMe3 to develop their own test scripts, so we have compiled this PyNVMe3 script development guide for SSD develop and test engineers.
1. Test platform
PyNVMe3 is a pure software test tool, can work on a variety of computers and servers. Users do not need to spend a lot of money to buy a dedicated test hardware platform. It is convenient for manufacturers to deploy testing at low cost and on a large scale. Before installing PyNVMe3, please check that the platform meets the following requirements:
- CPU: x86_64 platform. AMD platforms require to add kernel boot parameters, please refer to the Installation and Configuration section below.
- OS: Ubuntu LTS (e.g. 22.04), it is recommended to install OS on SATA disk.
- Sudo/root access is required.
- RAID mode (Intel® RST) needs to be disabled in the BIOS.
- Secure boot needs to be disabled in the BIOS.
The server platform requires additional considerations:
- IOMMU: (a.k.a. VT for Direct I/O) needs to be disabled in the BIOS.
- VMD: needs to be disabled in the BIOS.
- NUMA: needs to be disabled in the BIOS.
1.1 Preparation
First of all, to install Ubuntu LTS, it is recommended to use SATA SSD as the OS disk.
Ordinary users often need to enter a password when using sudo to obtain root privileges, which is a bit troublesome. We recommend that you configure the following password-free first:
- Execute the following command in the Ubuntu LTS command line environment, and the system will automatically open the default editor nano.
> sudo visudo - On the last line, enter
your_username ALL=(ALL) NOPASSWD: ALL - Ctrl-o and enter to write the configuration file. Then use Ctrl-x exits the editor. You don’t need to enter the password anymore if you use sudo later.
1.2 Installation
PyNVMe3 needs to be installed from the command line in the terminal, and we have done most of the automation processing, so the installation is not complicated. The specific process is as follows:
- Update Ubuntu
> sudo apt update > sudo apt upgrade - On Ubuntu 24.04, disable PEP 668. So we can install python packages into the system.
> sudo rm -f /usr/lib/python3.12/EXTERNALLY-MANAGED - PyNVMe3 uses a lot of python libraries, so you need to install pip3 first.
> sudo apt install -y python3-pip - (Optional) users can change the source of pip3. Create or modify the file ~/.pip/pip.conf, and add the following lines before saving.
[global] index-url=https://pypi.tuna.tsinghua.edu.cn/simple/ [install] trusted-host=pypi.tuna.tsinghua.edu.cn - If you have previously installed PyNVMe3, uninstall PyNVMe3 first
> sudo pip3 uninstall PyNVMe3 > sudo rm -rf /usr/local/PyNVMe3 - Install PyNVMe3 with pip3, and PyNVMe3 will be installed in the folder
/usr/local/PyNVMe3. If you do not have PyNVMe3 installation packages, please contact sales@pynv.me.> sudo pip3 install PyNVMe3-xx.yy.zz.tar.gz
1.3 Configuration
PyNVMe3 relies on Hugepage Memory to ensure efficient communication between software and hardware (e.g., DMA) as well as between different processes (e.g., ioworkers). Hugepages are physically contiguous memory blocks that are fixed in memory and cannot be swapped out by the operating system. This makes them crucial for achieving high performance and low latency during NVMe SSD testing.
By default, the make setup command reserves 10GB of hugepage memory, consisting of 2MB hugepages. However, some scenarios require additional memory (e.g., testing high-capacity SSDs or multiple SSDs simultaneously). In such cases, additional 1GB Hugepages need to be configured during kernel initialization. The GRUB configuration steps are outlined below.
- Modify the GRUB Configuration
Open the/etc/default/grubfile with root privileges and update theGRUB_CMDLINE_LINUX_DEFAULTline as follows:GRUB_CMDLINE_LINUX_DEFAULT="quiet splash default_hugepagesz=2M hugepagesz=1G hugepages=18 iommu=off intel_iommu=off amd_iommu=off modprobe.blacklist=nvme pcie_aspm=off"hugepagesz=1G: Specifies the hugepage size.hugepages=18: Reserves 18GB of hugepage memory. Adjust this value based on your testing requirements.
- Update GRUB
Apply the changes by running the following command:sudo update-grub - Mount Hugepage Memory
Add the following line to the/etc/fstabfile to mount the hugepage memory at boot:none /mnt/huge hugetlbfs pagesize=1G,size=18G 0 0 - Reboot the System
Restart the system to activate the new configuration:sudo reboot
PyNVMe3 uses hugepage memory for critical data structures such as submission/completion queues, data buffers, and CRC (cyclic redundancy check) tables for data validation. The amount of hugepage memory required depends on the SSD capacity, LBA format, and the number of devices being tested.
Below are some typical scenarios to help calculate and configure Hugepage Memory.
Scenario 1: Testing a Single High-Capacity SSD. For example, testing a 16TB SSD formatted with 512-byte LBAs:
- CRC Table Requirement: The SSD contains 32G LBAs (16TB ÷ 512B = 32G LBAs). PyNVMe3 requires approximately 32GB of memory to store the CRC table.
- Recommended Configuration: Reserve 40GB of 1GB Hugepage Memory for the test to allow for additional overhead. Ensure the system has at least 64GB of physical memory.
- Alternative: If the SSD is formatted with 4KB LBAs, the number of LBAs reduces to 4G (16TB ÷ 4KB = 4G LBAs). The CRC table requires only 4GB of memory, which can be handled by the default hugepage allocation (
make setup).
Scenario 2: Testing Multiple SSDs on a Server. For example, testing 6 × 4TB SSDs formatted in 512B LBAs and 6 × 4TB SSDs formatted in 4KB LBAs:
- CRC Table Requirement:
- 6 SSDs @ 512B LBA: Each requires 8GB (4TB ÷ 512B = 8G LBAs).
- 6 SSDs @ 4KB LBA: Each requires 1GB (4TB ÷ 4KB = 1G LBAs).
- Total CRC Table Memory: 6 × 8GB + 6 × 1GB = 54GB.
- Per-DUT Memory Overhead: Reserve 2GB per SSD for additional usage. Total: 2GB × 12 = 24GB.
- Operating System Memory: Reserve 5GB for the OS and other processes.
- Total Hugepage Memory Requirement: 54GB + 24GB + 5GB = 83GB.
- Recommended Configuration: Equip the system with 128GB of physical memory and configure 100 × 1GB hugepages to ensure sufficient memory is available.
Scenario 3: Testing in Multi-Socket Server Environments. Multi-socket servers introduce additional considerations due to NUMA (Non-Uniform Memory Access).
- Hugepage Allocation Across Sockets
Hugepage memory is allocated separately for each CPU socket. PyNVMe3 ensures memory allocation aligns with the socket hosting the DUT for optimal performance. For instance, in the above example with 12 SSDs, if all 6 × 512B LBA SSDs are assigned to one socket, this socket requires 48GB hugepage memory, while the other socket (with 6 × 4KB LBA SSDs) requires only 6GB. This imbalance can lead to memory allocation failures despite unused memory on the second socket. To prevent this, evenly distribute SSDs across sockets, ensuring that each socket has enough hugepage memory for its assigned DUTs. - CPU-to-DUT Affinity
Assign CPU cores closest to the PCIe devices (DUTs) to handle operations, minimizing latency and maximizing throughput. This can be configured in theslot.conffile.
1.4 Execution
PyNVMe3 can be executed in several different ways:
- Executed under VSCode, it is mainly used to debug new scripts.
- Execute in a command-line environment.
- Executed in CI environments such as Jenkins.
We first introduce the test execution of PyNVMe3 through the command line environment.
- enter PyNVMe3 directory
> cd /usr/local/PyNVMe3/ - Switch to root
> sudo su - Configure the runtime environment. This step replaces the kernel driver of the NVMe device with the user-mode driver of PyNVMe3 and reserves large pages of memory for testing.
> make setupBy default, PyNVMe3 will try to reserve 10GB of huge-page memory, which can meet the test needs of a 4TB capacity disk (LBA size of 512 bytes). It is recommended that the test machine be equipped with 16G or more memory. For details of huge-page memory, please refer to the Buffer section below.
- Use the following command to execute the test:
> make testThis command executes all test projects in the folder
scriptsconformance by default. The conformance test suite contains comprehensive test scripts against NVMe specification, which normally completes in 1-2 hours.There are more tests in the folder
scripts/benchmark. The benchmark test usually takes a longer time to execute, from a few hours, days, to weeks. We need to specify the file name in the command line.> make test TESTS=scripts/benchmark/performance.pyIf there are multiple NVMe devices under test on the test platform, we can specify the BDF address of the DUT in the command line. Alternatively, we can specify the
slotof DUT in the command line, and PyNVMe3 can find the BDF address of the DUT in that slot.> make test pciaddr=0000:03:00.0 > make test slot=3If there is only one NVMe disk on the platform, you do not need to specify this parameter, PyNVMe3 will automatically find the BDF address of this disk. This is why we recommend using SATA disk to install OS system.
For NVMe disks with multiple namespaces, you can specify the test namespace through the nsid parameter, and the default condition is 1.
> make test nsid=2We can use a combination of TESTS/pciaddr/nsid parameters in make test command line.
- Collect test results. After the test starts, the test log will be printed in the terminal, as well as the test log file in the folder
resultswhere we can find more information for debugging. Each test item may have the following results:- SKIPPED: The test was skipped. Test doesn’t need to be executed due to some conditions not being true.
- FAILED: The test failed. The log file shows the specific reason for the test failure, usually an assert that is not satisfied. When an assert fails, the test exits immediately and will not continue with subsequent test items.
- PASSED: Test passed
- ERROR: The test could not be executed. The DUT possibly has been lost, and cannot be detected by PyNVMe3. If you encounter ERROR, it is recommended to check the log of the previous FAILED test case, which could caused the DUT in problem.
Regardless of the test results, it is possible to generate a warning during the test. The test log contains a list of all warnings. Most warnings may be related to the error code in CQE returned by the DUT, or an AER command returned. Warnings do not stop the test execution, but we recommend double-checking all warning information.
The results directory contains not only the test log file, but also the files (excel, csv, or png) generated by the test script (such as the raw data and diagrams of the test record, etc.).
make testcommands will automatically switch back to the kernel inbox NVMe driver after the test is completed normally. Users can also manually switch to kernel inbox NVMe drivers by the command line below in order to execute other kernel-based tools (e.g. fio/nvme-cli, etc.).> make resetAs the opposite operation of
make setup,make resetswitches back to the kernel driver for the NVMe device. However, it does not free the huge-page memory reserved bymake setup. Because once these memories are freed, due to memory fragmentation, subsequentmake setupcommands are likely to be unable to acquire enough huge-page memory again. Therefore, we also recommend that users executemake setupas soon as the OS is started to ensure that the required huge-page memory can be reserved.pytest.inifile is used to configure settings and preferences for running tests using the pytest framework. Each parameter in the file has a specific purpose:testpaths: Directories where pytest looks for tests (scriptsin this case).log_cli_level: Sets the logging level for console output (INFOhere).log_driver_level: Sets the logging level for the driver/spdk, with numerical values indicating severity.filterwarnings: Configures warnings, allowing specific warnings to be ignored.addopts: Additional options for running pytest, like verbosity, report formats, etc.
This configuration influences how pytest finds and executes tests, handles logging, and manages warnings. It’s crucial for maintaining consistency and control in test environments.
2. pytest
PyNVMe3 is a complete NVMe SSD test platform, but our main work focus on the device driver which is packaged into a Python library. People can use PyNVMe3 by calling our APIs. In this way, our tools can be fully integrated into the Python ecosystem and leverage various third-party tools in this mature ecosystem. Pytest is one of the examples.
Pytest is a generic testing framework that helps test developers write all kinds of test scripts from simple to complex. Below, we introduce some basic usage and features of pytest, please refer to the official pytest documentation for more details.
2.1 Write a test
Pytest automatically collects functions starting with test_ in the test script as test functions. Pytest then calls these test functions one by one. Below is a complete test file.
import pytest
def test_format(nvme0n1):
nvme0n1.format()
Yes, there are only 3 lines, and this is a complete pytest file. Its test script is very concise. The test file only needs to import the pytest module, and then you can implement the test function directly.
When we don’t want to execute a test function, it is recommended to add an underscore _ at the beginning of the function name, pytest will not collect this test function, for example:
import pytest
def _test_format(nvme0n1):
nvme0n1.format()
2.2 Command line
Pytest supports several ways to execute tests from the command line. As mentioned earlier, PyNVMe3 uses the make test command line to execute tests, but it is also possible to execute tests directly using the pytest command line. For example, the following command lines are used to execute all tests in a directory, all tests in a file, and a specified test function respectively.
> sudo python3 -B -m pytest scripts/conformance
> sudo python3 -B -m pytest scripts/conformance/01_admin/abort_test.py
> sudo python3 -B -m pytest scripts/conformance/01_admin/abort_test.py::test_dut_firmware_and_model_name
2.3 Assert
We can use Python’s standard assert statement to verify test points in pytest scripts, for example:
def inc(x):
return x + 2
def test_inc():
assert inc(1) == 2, "inc wrong: %d" % inc(1)
The assert above fails due to the incorrect implementation of the inc function. pytest reports test FAIL and prints specific information about the failure, including the string after the comma in the assert statement. We can debug scripts and firmware based on this information in the log files. A good assertion can provide enough information about the FAIL scenario to improve the efficiency of development and debugging.
2.4 fixture
Pytest has a very important feature called Fixture. Fixture is the essence of Pytest. Here we introduce the basic usage of Fixture through some examples. For more detailed content, please refer to the official fixture documentation.
The following script contains two fixtures: nvme0 and nvme0n1, and a test function that uses these two fixtures.
@pytest.fixture()
def nvme0(pcie):
return Controller(pcie)
@pytest.fixture(scope="function")
def nvme0n1(nvme0):
ret = Namespace(nvme0, 1)
yield ret
ret.close()
def test_dut_firmware_and_model_name(nvme0: Controller, nvme0n1: Namespace):
# print Model Number
logging.info(nvme0.id_data(63, 24, str))
# format namespace
nvme0n1.format()
As you noticed, Fixture is just a function, but decorated with @pytest.fixture(). It is used to initialize the objects used in the test functions. The fixture name should not start with test to distinguish from the test functions. To use a fixture, simply add the fixture name to the parameter list of the test function. When executing the test, pytest will call the Fixture’s function and pass the return object to the name of the Fixture in test function’s parameter list. After that, the test function can use the object directly.
Fixture encapsulates the creation and release of objects used by test functions. PyNVMe3 defines many frequently used objects for NVMe testing, such as: pcie, nvme0, nvme0n1, qpair, subsystem, and etc. With these fixtures, we don’t need to write code repeatedly in each test function to create or release test objects. You can add as many fixtures as you want to the parameter list of the test function.
Fixture returns the initialized objects by the return or yield statement. The code after yield will be called again by pytest after the test is completed, which usually release the test objects.
Fixtures can depend on each other, for example, nvme0n1 in the above script depends on nvme0. If the test function references both fixtures, pytest can decide the order of fixture calling according to their dependency, no matter how many fixtures the test function used.
Fixture contains an optional parameter called scope, which controls when the fixture is called. Take nvme0 above as an example, its scope is function, so pytest will call nvme0 before each test function is executed, so that each test function will reinitialize the NVMe controller, which can isolate the error of different tests. If we change it scope to session, the controller will only be initialized once in the whole session of the test.
Fixtures can be overloaded. The fixture defined within the same test file has the highest priority. Fixture can also be placed in conftest.py file, which is defined by pytest specifically for fixtures. Different directories can have different conftest.py files, and pytest use the nearest definition of the fixture when executing a test function.
PyNVMe3 provides online help documentation, but the IDE does not know the type of the fixtures, so it needs to use type hints. For example, in the following script, the IDE is told that nvme0 is a Controller object, so that the IDE can find and display the help documentation for nvme0 and its methods id_data.
def test_dut_firmware_and_model_name(nvme0: Controller, nvme0n1: Namespace):
# print Model Number
logging.info(nvme0.id_data(63, 24, str))
# format namespace
nvme0n1.format()
All in all, pytest’s fixture is a concise and extensible test framework. PyNVMe3 defines and uses fixtures extensively.
2.5 Parameterize
Test cases are often parameterized, such as writing data of different LBA lengths at different LBA start addresses. Pytest provides a convenient way to implement it. For example, in the following test script, pytest will execute this test case with all different combinations of lba_start and lba_count. There are totally 4×4=16 test cases.
@pytest.mark.parametrize("lba_start", [0, 1, 8, 32])
@pytest.mark.parametrize("lba_count", [1, 8, 9, 32])
def test_write_lba(nvme0, nvme0n1, qpair, lba_start, lba_count):
buf = Buffer(512*lba_count)
nvme0n1.write(qpair, buf, lba_start, lba_count).waitdone()
Here is a short introduction of pytest. It is a great generic test framework. We can explore it deeper in our test scripts development.
3. Visual Studio Code (VSCode)
Sharp tools make great work. To write a good script, you need to find an IDE easy to use. We recommend VSCode. VSCode, an official Microsoft open source project, is a lightweight but rapid extended code editor that can be used on Windows, MacOS, and Linux. In addition, Microsoft also officially provides plugins that support Python, and continuously improves them. PyNVMe3 also provides an extension (aka. plugin) for VSCode to display test information such as queues, command logs, and the performance meters. VSCode is mainly used for developing and debugging test scripts, and we still recommend using a command line environment or a CI environment for formal execution of tests.
Usually, we setup different test machines in the lab, but we don’t want to debug the code in the lab for a long time. VSCode supports remote working, you only need to install VSCode on your own working machine, and remotely link to the test machine through SSH to develop and debug the test scripts. The experience is exactly the same as local work. Now, we introduce the steps to setup this remote VSCode.
- Download VScode software installation package from the official web-site and install VSCode on the working machine. The working machine can be Windows, Linux, or MacOS.
- Install the Remote-SSH extension.
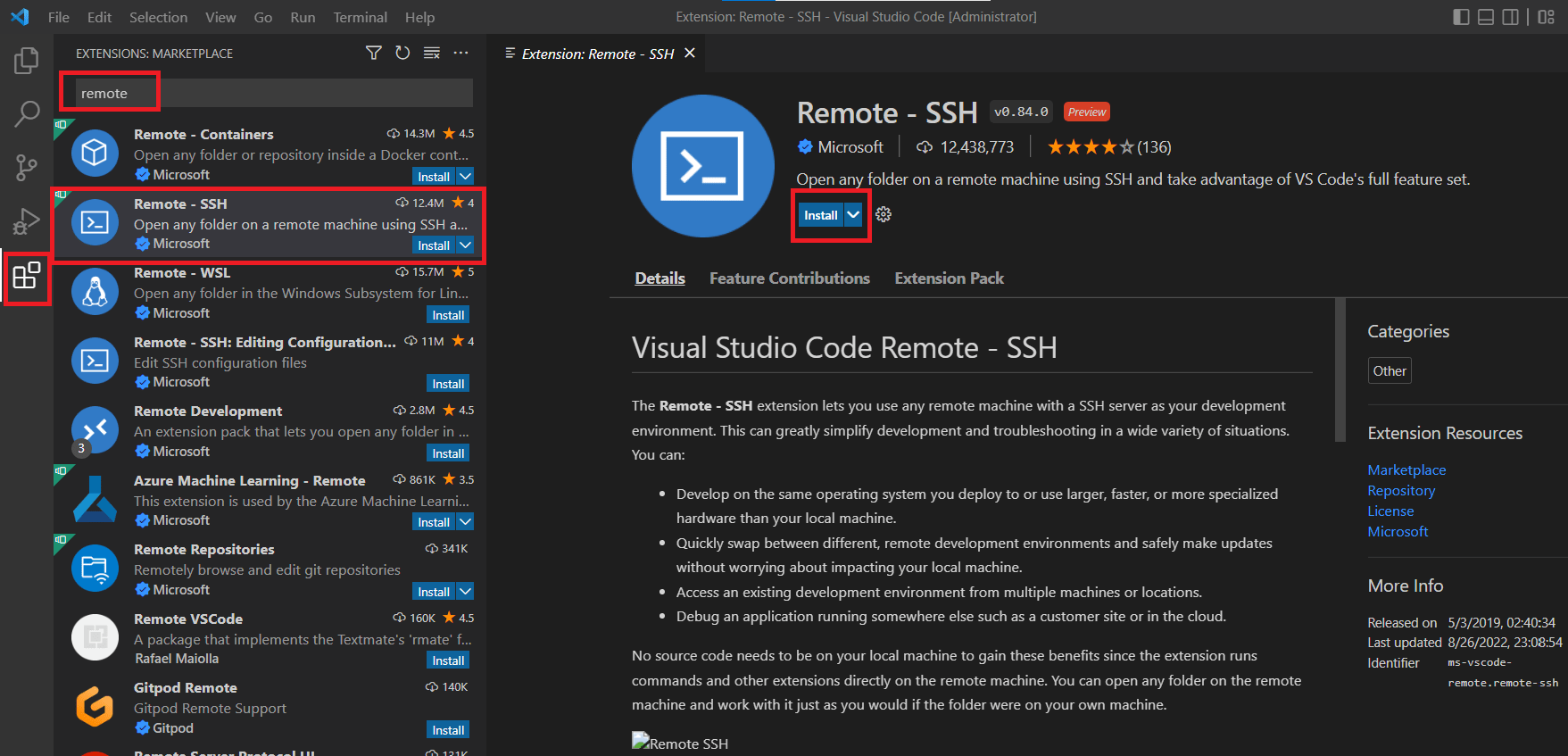
If you want to log in remotely using therootaccount of the test machine, you need to change the SSH configuration of the test machine.> sudo vim /etc/ssh/sshd_configFind and comment out the line with #:
PermitRootLogin prohibit-passwordThen add a new line:
PermitRootLogin yesand restart SSH server in test machine:
> sudo service ssh restart # Restart SSH service > sudo passwd root # Need to set password for root account - In VSCode installed in your working machine, we now can add test machines to Remote-SSH targets. Click the icons in the red in the figure below from left to right, and enter the ssh command line, you can specify the custom ssh port with the parameter -p. Then press enter.
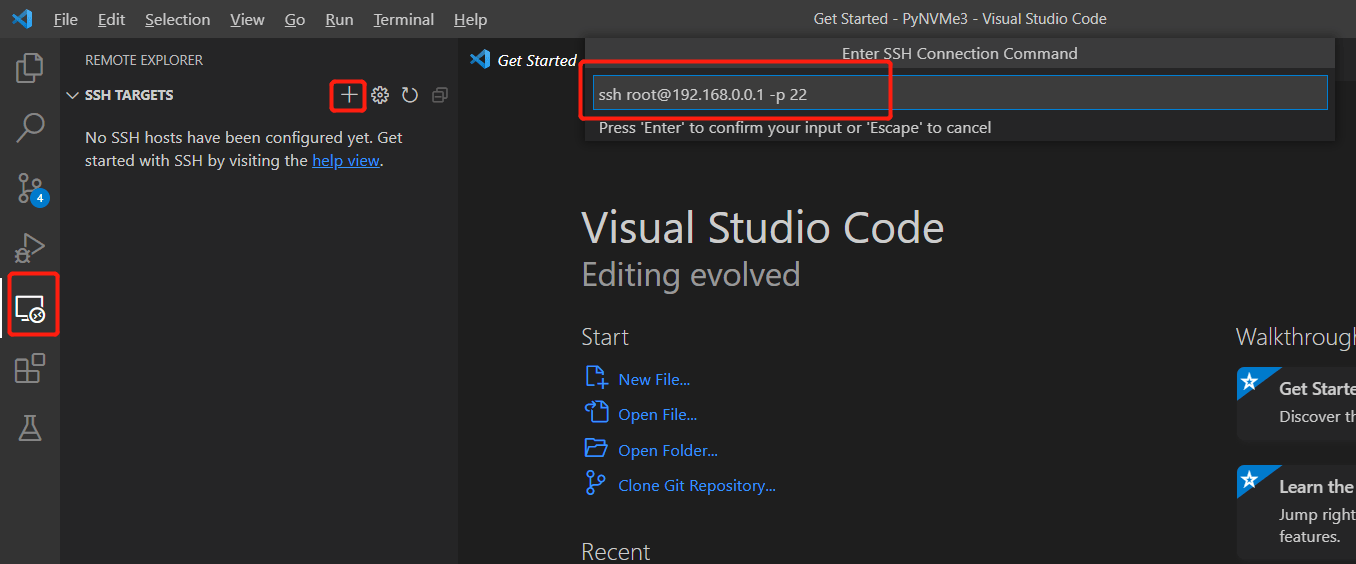
- A new VSCode window will pop up. We can install the PyNVMe3 extension now. Click install from VSIX, find the extension package in the folder
PyNVMe3/.vscode.
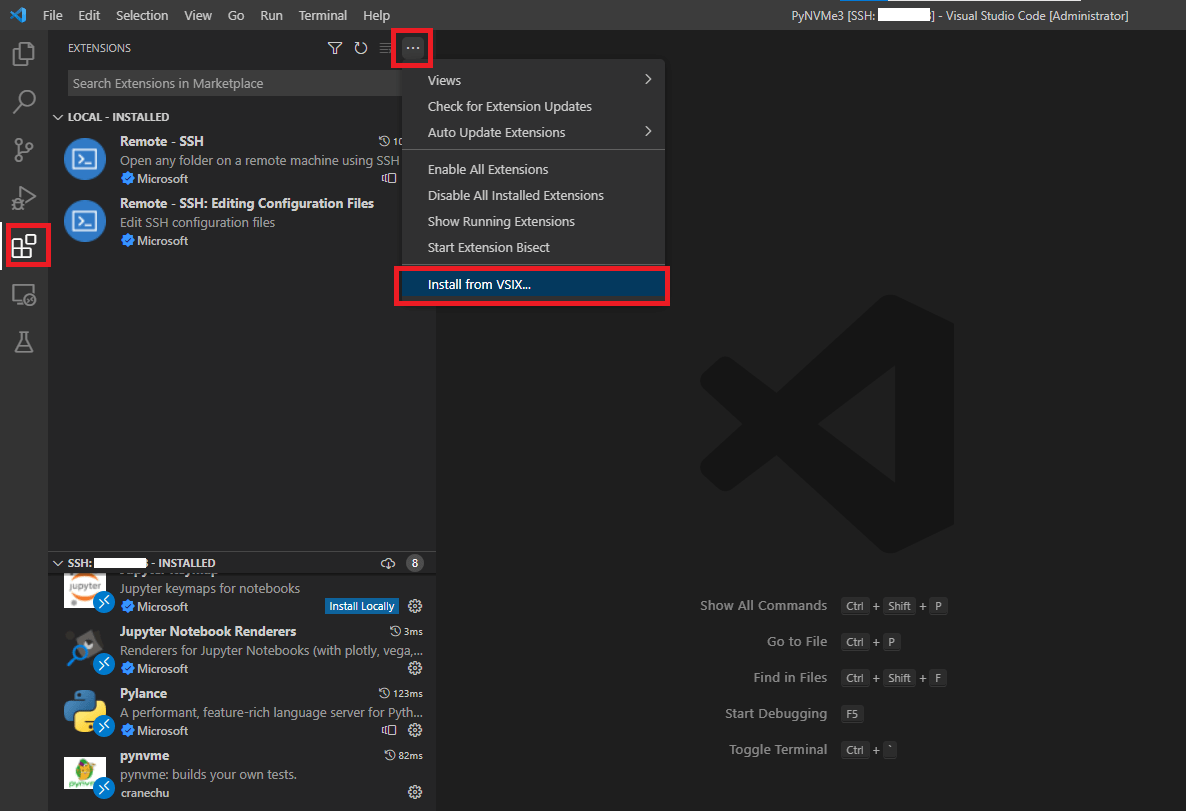
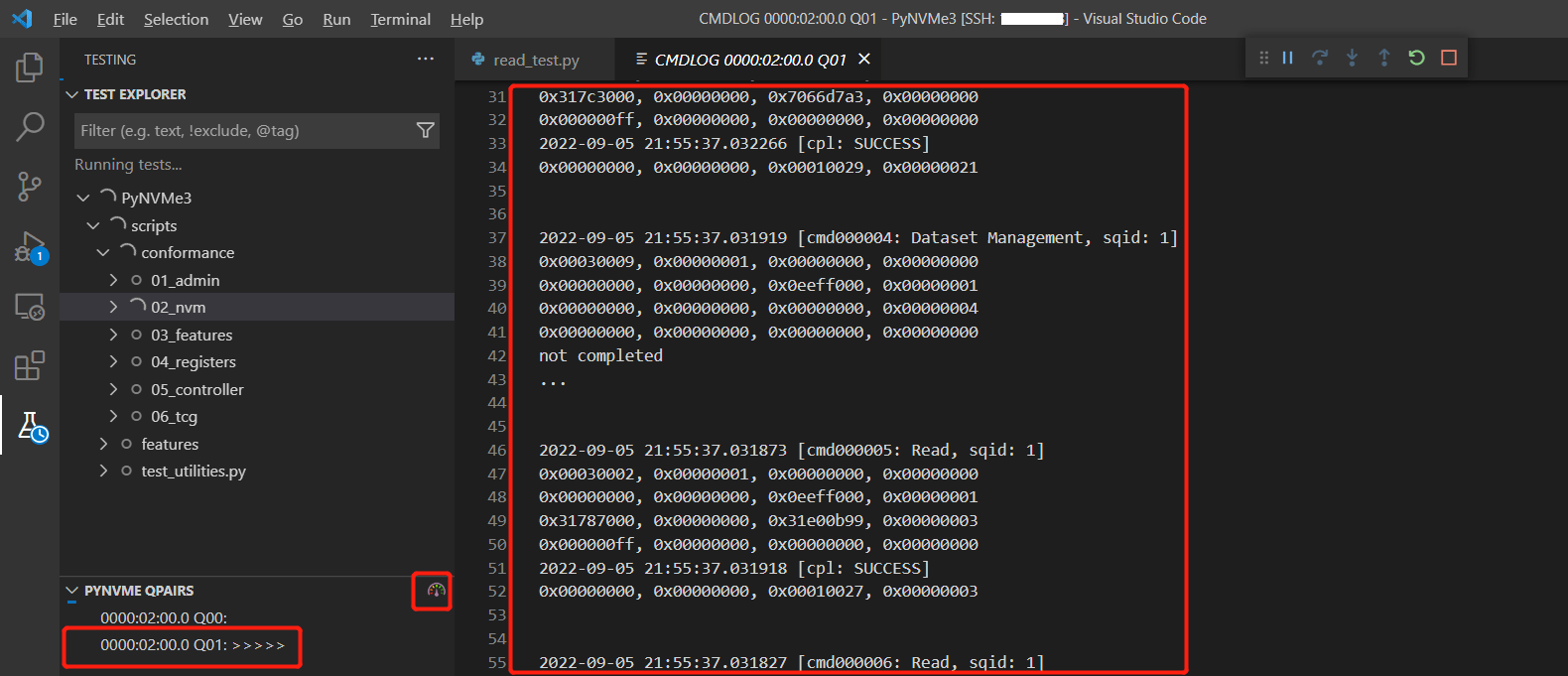
- As shown in the figure below, PyNVMe3 extension can display the current queue, commands and performance information in VSCode.
- Open the PyNVMe3 folder in the VSCode remote window.
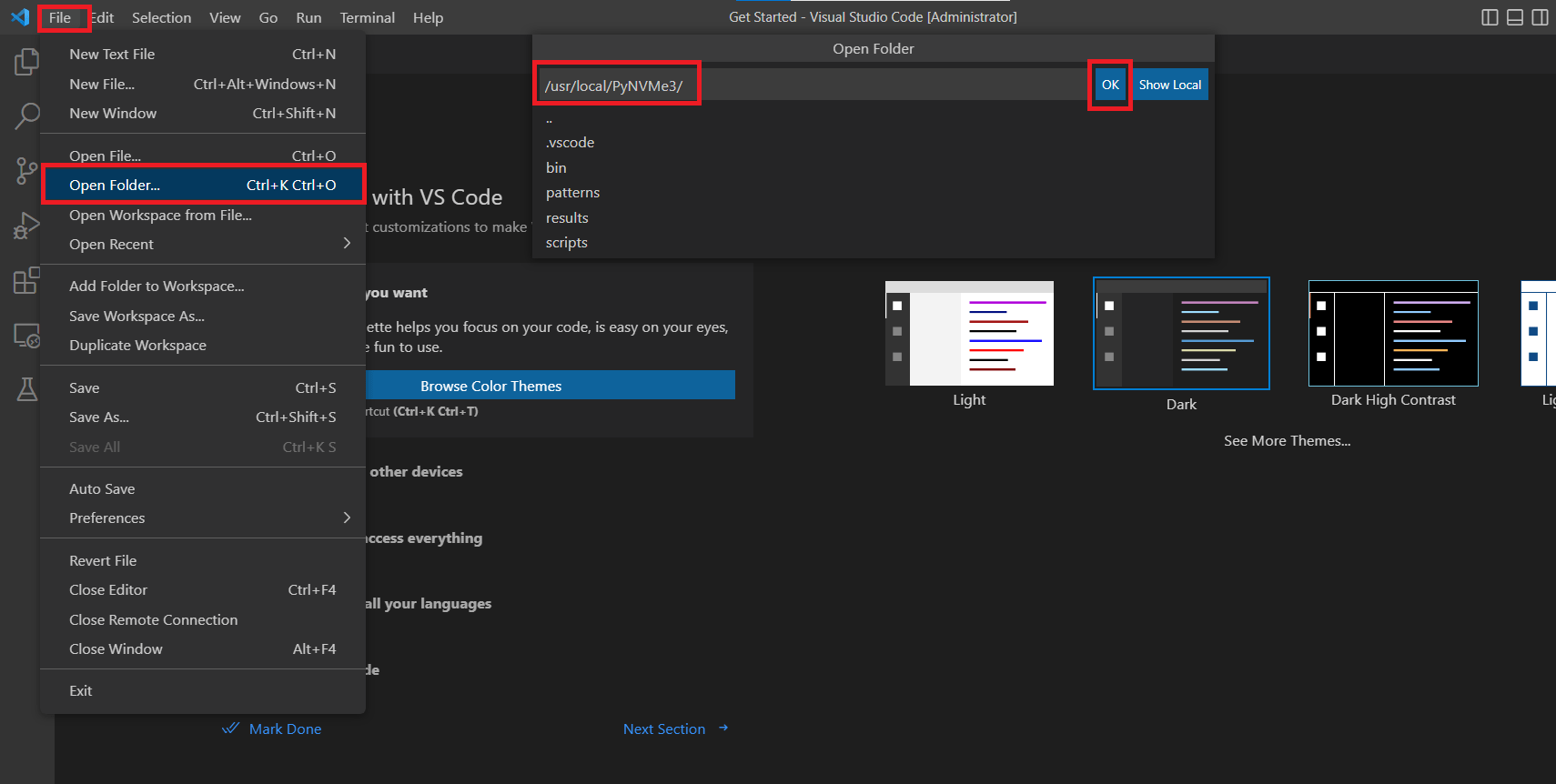
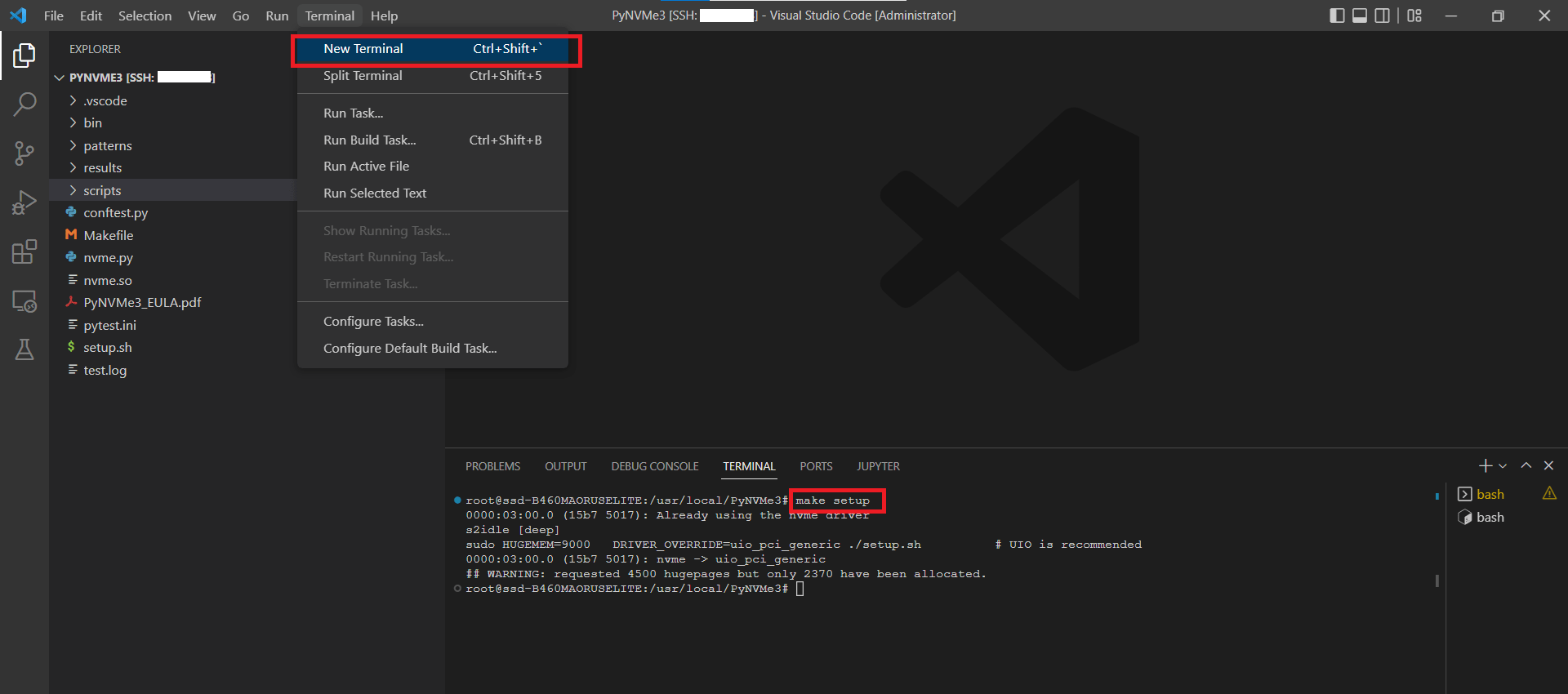
- Open a terminal and execute
make setupcommand.
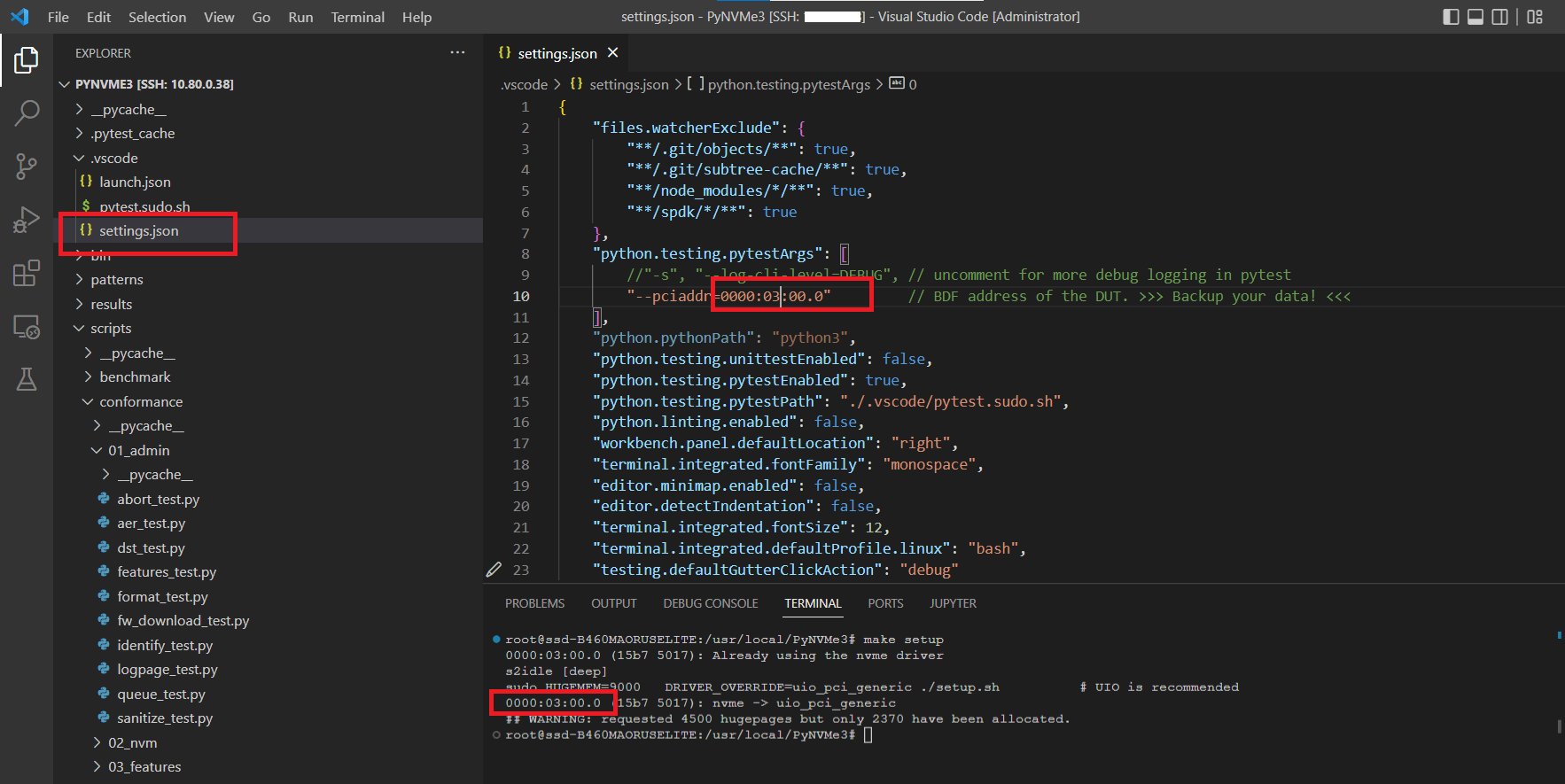
- Configure the BDF address of the NVMe device in file
setttings.json. You can find the BDF address in the output ofmake setupcommand.
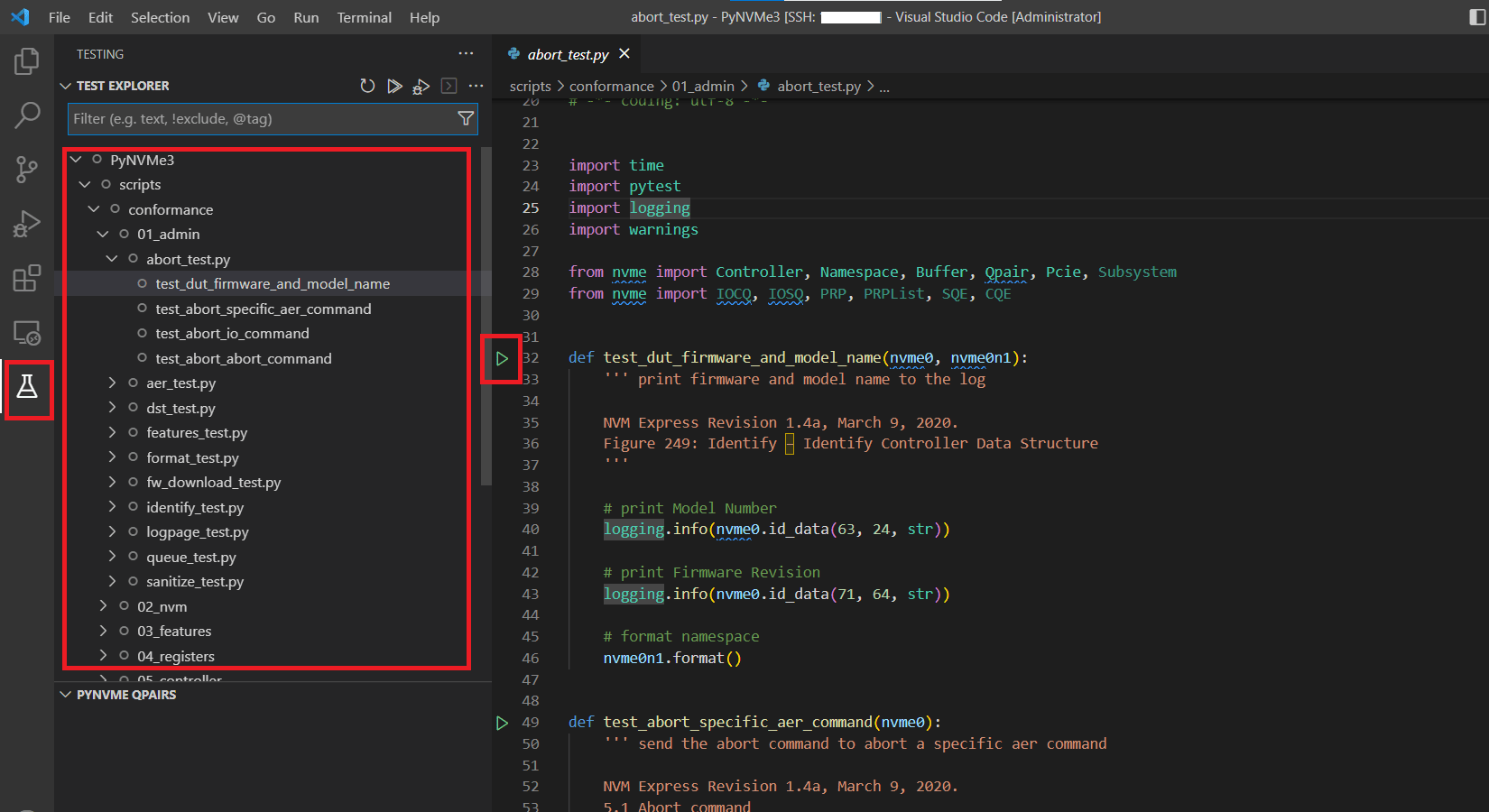
- Pytest extension for VSCode collects test functions of PyNVMe3. Click the icon on the left to expand the test-related pane, which will display all the test cases collected by pytest. Click the triangle button to the left of the line number of the test function to run the test. For parameterized test cases, you need to right-click the triangle button to select one for a time.
- When VSCode executes a test, you can also find the test log in the terminal interface, but the log file will not be saved in the
resultsfolder.
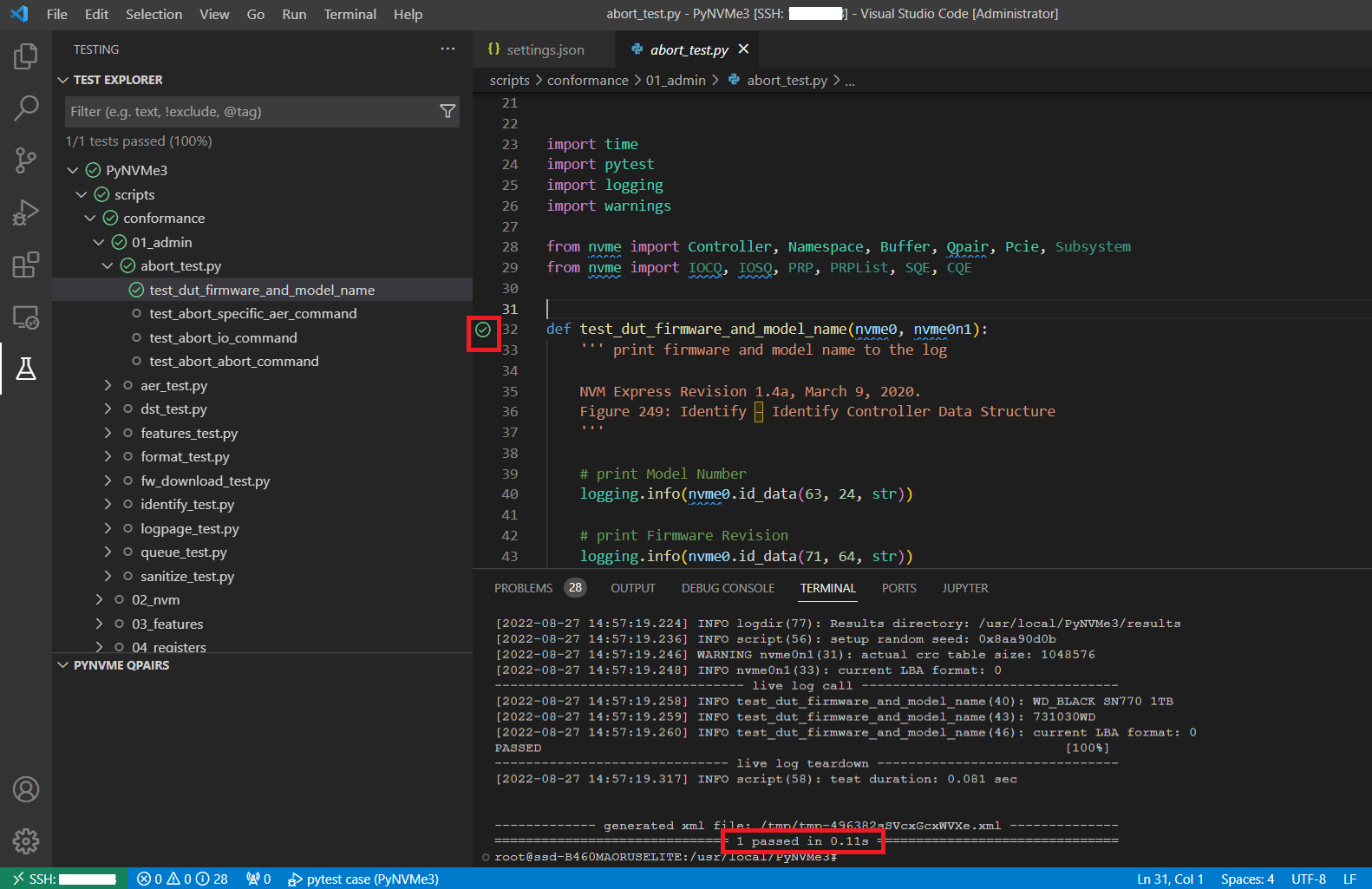
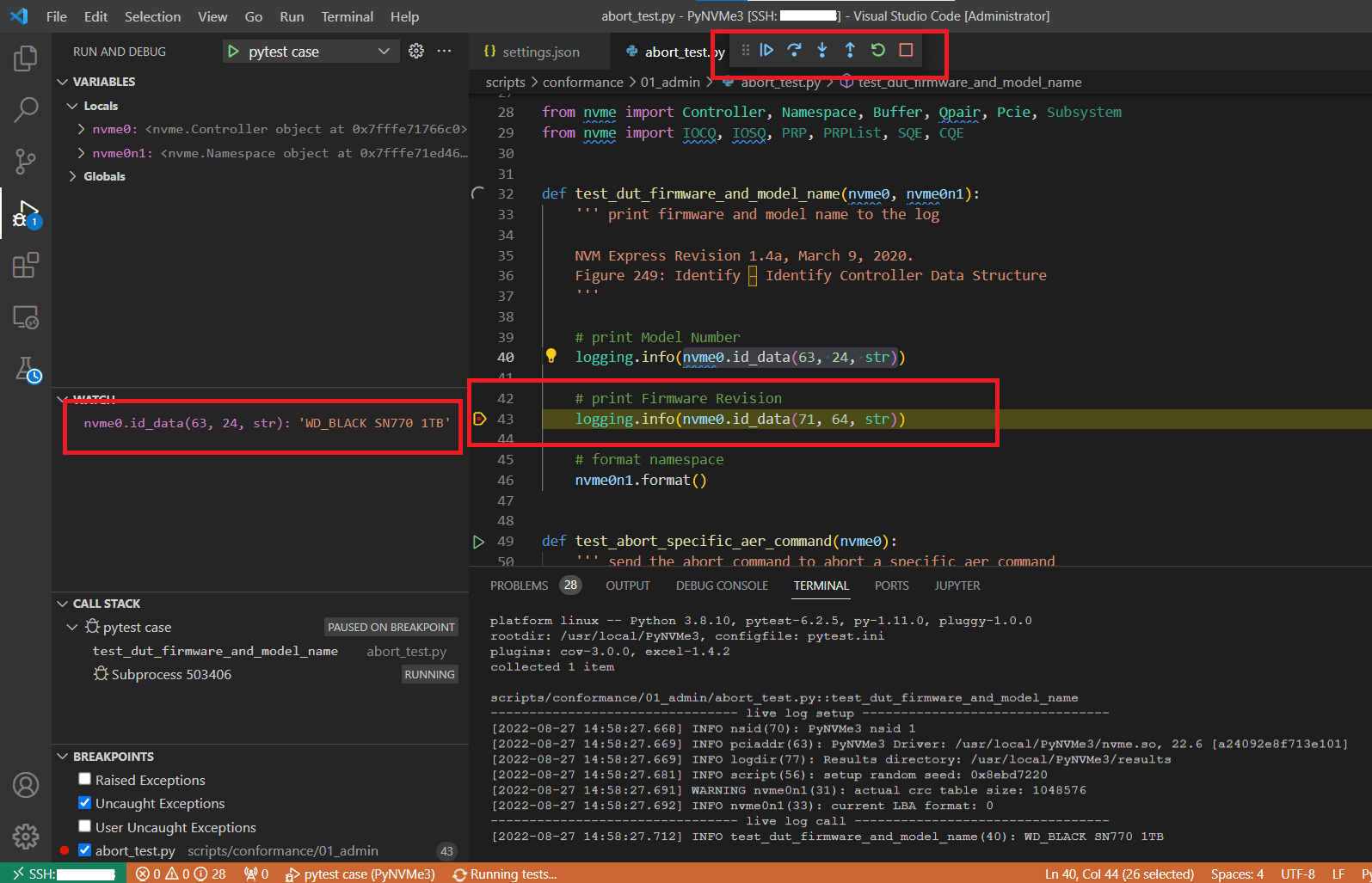
- VSCode performs tests in Debug mode. You can add breakpoints to test scripts, and watch python variables in debug pane. After the breakpoint is triggered, the PyNVMe3 extension is still working, and you can exam the queue and command logs when the script is stopped, making debugging easier. But please be noted that the PyNVMe3 driver has a timeout threshold. When the breakpoint stops the script, it may cause the outstanding command timeout. So, please avoid setting breakpoints where there is an outstanding command.
4. Basic script
Once the hardware and software platform for PyNVMe3 are ready, we can start writing test scripts for NVMe SSDs.
Each test script needs to import some modules, including pytest, logging, and of course, the PyNVMe3 driver module (nvme.so). Below is a typical complete test script.
import pytest
import logging
from nvme import *
def test_dut_firmware_and_model_name(nvme0: Controller):
logging.info("model name: %s" % nvme0.id_data(63, 24, str))
logging.info("current firmware version: %s" % nvme0.id_data(71, 64, str))
logging.info("PyNVMe3 conformance test: " + __version__)
We directly import all the classes and variables provided by PyNVMe3, which has commonly used classes: Controller, Namespace, Qpair, and etc. __version__ can get the version of the imported PyNVMe3 driver module.
PyNVMe3 can do any work on NVMe devices, but let’s first quickly explore several basic scripts of PyNVMe3 through read and write operations. PyNVMe3 supports 3 different ways to send IO to meet different testing requirements.
4.1 ns.cmd
ns.cmd is a simple and direct way to send IO in asynchronous way. We can send read, write, trim, write uncorrectable, and other IO commands. PyNVMe3 provides API for almost all IO commands.
ns.cmd sends commands via qpair, which consist of a SQ and a CQ. PyNVMe3 defines a default namespace fixture with nsid of 1, called nvme0n1 according to the naming convention of Linux kernel drivers. Below is an example of a test function that sends read and write commands to nvme0n1 using qpair, and you can see that pytest’s fixture makes its implementation very concise.
def test_write_read(nvme0n1, qpair):
read_buf = Buffer(4096)
write_buf = Buffer(4096)
nvme0n1.write(qpair, write_buf, 0).waitdone()
nvme0n1.read(qpair, read_buf, 0).waitdone()
After the script issues a command, it does not wait for the command to return, but directly continues to execute following scripts. If we need to wait for the command to complete, we can call API waitdone().
NVMe is an asynchronous IO protocol, and system drivers often use a callback mechanism to handle operations after this IO is completed. PyNVMe3 also provides callbacks mechanism, allowing test scripts to define the processing code after each IO command completes. The callback function is called in waitdone() by the PyNVMe3 driver.
The following test function has the identical behavior as the above example, but the read command is issued in the callback of the write command. Since the callback function is called in waitdone, PyNVMe3 does not support calling waitdone() in the callback function. Instead, here we call waitdone() to reap 2 commands in one shot.
def test_io_callback(nvme0, nvme0n1, qpair):
read_buf = Buffer(4096)
write_buf = Buffer(4096)
def write_cb(cqe):
nvme0n1.read(qpair, read_buf, 0)
nvme0n1.write(qpair, write_buf, 0, cb=write_cb)
qpair.waitdone(2)
PyNVMe3 driver pass the CQE returned by DUT to the callback function.
def test_io_callback(nvme0n1, qpair):
write_buf = Buffer(4096)
# issue write and read command
cdw0 = 0
def write_cb(cqe): # command callback function
nonlocal cdw0
cdw0 = cqe[0]
nvme0n1.write(qpair, write_buf, 0, 1, cb=write_cb).waitdone()
4.2 ioworker
We can use scripts to send a lot of IO through ns.cmd, but the efficiency of both development and execution is very low. PyNVMe3 provides an IO generator: ioworker. Ioworker sends and reclaims IO autonomously according to the workload specified by the script. Ioworker can produce high-performance IO workload: a single-core can achieve more than 1.2 million IOPS in mainstream test platforms. The script creates the ioworker object through the API Namespace.ioworker(), and then start the ioworker through its start() method. At this point, ioworker runs in the child process, and the main process of the script can perform other operations. The script waits for the ioworker child process to complete through the close() method. Below is an example of using ioworker to send 4K aligned random write for 2 seconds.
def test_ioworker(nvme0, nvme0n1, qpair):
r = nvme0n1.ioworker(io_size=8, # 4K io size
lba_align=8, # 4K aligned
lba_random=True, # random
read_percentage=0, # write
time=2).start().close()
PyNVMe3 implements the with statement for ioworkers, making scripts more readable. For example, the following script creates and starts an ioworker, and when the ioworker is running, the main process prints the current performance data every other second. Of course, the main process can do anything else, including sending admin and IO commands, and even various reset and power cycle events.
with nvme0n1.ioworker(io_size=8, time=10) as w:
while w.running:
time.sleep(1)
speed, iops = nvme0.iostat()
logging.info("iostat: %dB/s, %dIOPS" % (speed, iops))
Ioworker provides a lot of functionality for SSD testing. It can directly create various IO workloads in Python scripts, and return various statistics data. We’ll go on to introduce the ioworker further in later chapters.
4.3 metamode
Both ns.cmd and ioworker work on top of PyNVMe3’s NVMe driver. They are easy to use, but subject to the limitations of the NVMe driver. PyNVMe3 also provides the third IO operation called metamode IO. This operation can bypass the NVMe driver of PyNVMe3 and directly test the NVMe SSD as a raw PCIe device, which can achieve full test coverage of the NVMe protocol. Metamode requires test scripts to define data structures such as IOSQ/IOCQ/SQE/CQE/PRP/SGL, and the Doorbell. Those data are located in the memory shared with the DUT, and the memory are created by the Buffer objects. It increases the complexity of the script implementation, but also greatly improves the ability and coverage of the test script.
The following script uses metamode to issue two commands with the same CID at the same time. This kind of error injection is difficult to implement with traditional test software.
def test_metamode_write(nvme0):
cq = IOCQ(nvme0, 1, 10, PRP(10*16))
sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq)
sqe = SQE(1<<16, 1)
sq[0] = sqe
sq[1] = sqe
sq.tail = 2
We introduced 3 different IO methods provided by PyNVMe3. In the following chapters, we will dive into the classes and methods provided by PyNVMe3, as well as explanations of these APIs. To simplify the details, subsequent scripts assume that the LBA size is 512-byte.
5. Buffer
NVMe/PCIe is a protocol based on shared memory design, and so the memory buffer is used often in test scripts to store user data, queues, PRP/SGL, PRP List and etc. The Buffer object is used for these shared memory.
- The
Bufferobject manages a consecutive and fixed physical memory region. The buffer is allocated in the huge-page memory, so they will not be swapped in and out by the OS. Because it always exists on a consecutive and fixed physical space,Buffercan be used as DMA memory and share data between host and DUT. In the example below, we have created a 512-byte buffer for the read command.def test_read(nvme0n1, qpair): read_buf = Buffer(512) nvme0n1.read(qpair, read_buf, 0, 1).waitdone()Earlier we mentioned reserving huge-page memory by command
make setup. The memory requested by theBufferobject comes from these reserved huge-page memories. If you need to create a Buffer larger than 1MB, you have to enable 1GB huge-page memory. When memory allocation fails, Buffer object throws an exception. - The
Bufferobject can also be used as the range list for DSM commands. PyNVMe3 provides APIBuffer.set_dsm_range()to fill the range to the Buffer.def test_trim(nvme0n1, qpair): buf_dsm = Buffer(4096) buf_dsm.set_dsm_range(0, 1, 1) buf_dsm.set_dsm_range(1, 2, 1) buf_dsm.set_dsm_range(2, 3, 1) nvme0n1.dsm(qpair, buf_dsm, 3).waitdone() - The
Bufferclass contains propertieslength,offsetandsize. Their relationship is shown in the following figure.0 offset length |===============|===================================| |<========= size =========>|
length is the length of physical memory, but the memory actually holding data starts from the offset. PyNVMe3 generates PRP/SGL of the Buffer according to offset and size values. By default, offset=0, size=length. Depending on the test target, the script can adjust the offset and size of the buffer object to construct specific PRP and SGL. It should be noted that offset+size must be less than or equal to the length, otherwise overflow access may occur.
def test_prp_page_offset(nvme0n1, qpair):
read_buf = Buffer(512+3)
read_buf.offset = 3
read_buf.size = 512
nvme0n1.read(qpair, read_buf, 0, 1).waitdone()
Buffercan be used as HMB. The HMB (Host Memory Buffer) is a portion of the memory reserved by the system, and used entirely by the DUT. It is necessary to pay special attention to theseBufferobject’s life cycle. When no variable refers to theBufferobject, it can not be reclaimed by Python GC. When the HMB is alive and used by the DUT, the script has to maintain reference to allBufferobjects used by HMB, otherwise, the some physical memory space would be re-allocated to other objects and HMB buffer would be corrupted. PyNVMe3 provides HMB librariesscripts/hmb.pyas well as test scripts scripts/conformance/03_features/hmb.Buffercan also be used as CMB. CMB (Controller Memory Buffer) is a portion of the physical memory located in NVMe SSD. Host system can map CMB memory to BAR space, and then read and write CMB for any purpose, like PRP/SGL, IOCQ/IOSQ, and even user data. TheBufferobject can get memory from the CMB space and is used to create IOSQ in the following script.def test_cmb_sqs_single_cmd(nvme0): cmb_buf = Buffer(10*64, nvme=nvme0) cq = IOCQ(nvme0, 1, 10, PRP(10*16)) sq = IOSQ(nvme0, 1, 10, cmb_buf, cq=cq)Buffercan be used by SGL testing. PyNVMe3 can generate the SGL mapping to theBufferobject when it is requested.def test_sgl_buffer(nvme0n1, qpair, buf): buf.sgl = True nvme0n1.read(qpair, buf, 0).waitdone()- PyNVMe3 inherits SegmentSGL, LastSegmentSGL, DataBlockSGL, and BitBucketSGL from the
Bufferclass to construct various SGL Descriptors. The following script implements the SGL example listed in the NVMe Specification. The total length of the data in this example is 13KB (26 LBA), divided into 3 SGLs:- seg0: Contains a 3KB block of memory and points to seg1;
- seg1: contains a 4KB block of memory and a 2KB hole, and points to seg2;
- seg2: is the last SGL and contains a 4KB block of memory.
The specific memory layout and corresponding PyNVMe3 scripts are as follows:
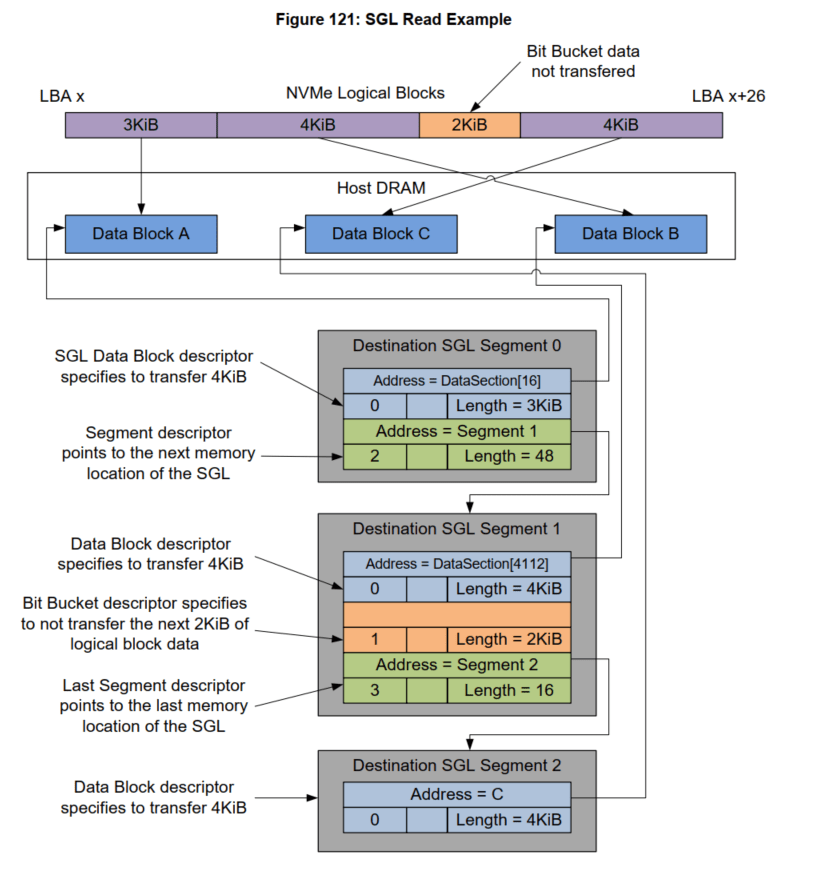
def test_sgl_segment_example(nvme0, nvme0n1): sector_size = nvme0n1.sector_size cq = IOCQ(nvme0, 1, 10, PRP(10*16)) sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq) sseg0 = SegmentSGL(16*2) sseg1 = SegmentSGL(16*3) sseg2 = LastSegmentSGL(16) sseg0[0] = DataBlockSGL(sector_size*6) sseg0[1] = sseg1 sseg1[0] = DataBlockSGL(sector_size*8) sseg1[1] = BitBucketSGL(sector_size*4) sseg1[2] = sseg2 sseg2[0] = DataBlockSGL(sector_size*8) sq.read(cid=0, nsid=1, lba=100, lba_count=26, sgl=sseg0) sq.tail = sq.wpointer cq.waitdone(1) cq.head = cq.rpointer sq.delete() cq.delete() - When the buffer is initialized, script can specify the pattern of the data with parameter ptype and pvalue, which defaults to all-zero data.
- The script can use array subscripts to read and write every byte in the buffer, or it can print the buffer’s data with API
Buffer.dump(). When you need to extract a field from the buffer, you can use the methoddatato specify the first and last addresses of the field and the type of data (default is int, you can also specify str to get a string). Thedatamethod is mainly used to parse the data structures returned by the DUT, such as identify data.buf = Buffer(4096, ptype=0xbeef, pvalue=100) logging.info(buf.dump(64)) logging.info(buf[0]) logging.info(buf.data(1, 0)) - The script can also directly use the == or != operators to compare the data of two buffers. For example:
assert buf1 == buf2 - The script can obtain the physical address of the buffer object’s memory space. This physical address is not the 0 address of the
Bufferobject, but the address atoffset. We can generate different PRP/SGL with differentoffsets.logging.info(buf.phys_addr)
Demonstrated with the above examples, the Buffer objects are frequently used in different scenarios, allowing test scripts to construct various NVMe tests on the basis of the shared memory.
6. Pcie
The NVMe protocol is based on the PCIe protocol, so an NVMe DUT is also a PCIe device. PyNVMe3 can create a Pcie object on DUT to provide PCIe level testing capabilities.
- Read and write the PCIe configuration space through subscript access or API.
- Look for capability with the API
Pcie.cap_offset(). It can find the offset address of the specified capability in the configuration space. - hot reset and FLR reset with API
Pcie.reset()andPcie.flr()respectively. After these resets, scripts have to call APIController.reset()to re-initialize the NVMe DUT.def test_pcie_flr_reset(pcie, nvme0): pcie.flr() nvme0.reset() - Read and write BAR0 space through a set of APIs.
def test_bar0_access(pcie, nvme0): assert pcie.mem_qword_read(0) == nvme0.cap Pcieobject also provides some PCIe attributes- speed, get or modify the speed of PCIe (Gen1-5).
- aspm, get or modify ASPM settings.
- power_state,get or modify the power state setting, e.g. D3hot.
Pcie is an essential class that separates all NVMe-related features to Controller class. Scripts can implement the NVMe initialization process on raw PCIe devices, which is impossible with Kernel’s inbox driver.
7. Controller
PyNVMe3 creates Controller object on Pcie object. Because NVMe specification defines Controller and Namespace separately, so PyNVMe3 also provides Controller classes and Namespace classes respectively. The script can create multiple Controller objects to meet the needs of multi-device, multi-port, SRIOV and other tests. Below we introduce the Controller class and the Namespace class respectively.
7.1 NVMe Controller Initialization
We can create Controller object as below:
def test_user_defined_nvme_init(pcie):
nvme0 = Controller(pcie)
nvme0.getfeatures(7).waitdone()
Or, we can use fixture nvme0 directly:
def test_user_defined_nvme_init(pcie, nvme0):
nvme0.getfeatures(7).waitdone()
Within Controller object creation, the driver can initialize NVMe controller following the steps defined in the NVMe specification. But PyNVMe3 allows script to override this initialization process. Below is a standard NVMe initialization process, but defined in user’s script.
def nvme_init_user_defined(nvme0):
# 1. disable cc.en
nvme0[0x14] = 0
# 2. and wait csts.rdy to 0
nvme0.wait_csts(rdy=False)
# 3. set admin queue registers
if nvme0.init_adminq() < 0:
raise NvmeEnumerateError("fail to init admin queue")
# 4. set register cc
nvme0[0x14] = 0x00460000
# 5. enable cc.en
nvme0[0x14] = 0x00460001
# 6. wait csts.rdy to 1
nvme0.wait_csts(rdy=True)
# 7. identify controller and all namespaces
identify_buf = Buffer(4096)
nvme0.identify(identify_buf).waitdone()
if nvme0.init_ns() < 0:
raise NvmeEnumerateError("retry init namespaces failed")
# 8. set/get num of queues
nvme0.setfeatures(0x7, cdw11=0xfffefffe, nsid=0).waitdone()
cdw0 = nvme0.getfeatures(0x7, nsid=0).waitdone()
nvme0.init_queues(cdw0)
# 9. send out all AER commands
aerl = nvme0.id_data(259)+1
for i in range(aerl):
nvme0.aer()
def test_user_defined_nvme_init(pcie):
nvme0 = Controller(pcie, nvme_init_func=nvme_init_user_defined)
In the script above, we create Controller object along with the user defined NVMe initialization function. So we can implement different NVMe initialization for different test cases, e.g. enabling Weighted Round Robin arbitration. But the test script should modify the NVMe initialization process and parameters referencing to the standard one above. An incorrect initialization process may cause DUT or driver misbehavior.
Do not change any timeout setting in your user-defined NVMe initializaiton funciton.
7.2 Admin commands
The Controller objects are used to send admin commands. PyNVMe3 provides APIs for most admin commands, including a generic interface Controller.send_cmd() to send any Admin commands.
def test_admin_cmd(nvme0, buf):
nvme0.getlogpage(2, buf, 512).waitdone()
nvme0.send_cmd(0xa, nsid=1, cdw10=7).waitdone()
They are all asynchronous operations to send commands. We can wait for command completion by API Controller.waitdone().
Moreover, script can specify a callback function for each command. After the command is completed, the PyNVMe3 driver will call the callback function of the command to handle the CQE (a list of 4 dwords) returned from DUT.
def test_callback_function(nvme0):
cdw0 = 0
def _getfeatures_cb(cqe):
nonlocal cdw0
cdw0 = cqe[0]
logging.info("getfeatures command completed")
nvme0.getfeatures(7, cb=_getfeatures_cb).waitdone()
num_of_queue = (cdw0&0xffff) + 1
Note that Controller.waitdone() can not be called inside any callback functions.
NVMe specification requires Controller to generate an interrupt when each admin command is completed. PyNVMe3’s Controller.waitdone() checks the interrupt signal before fetching CQE from the admin CQ. If there is no interrupt signal, Controller.waitdone will not return, when timeout error could happen.
The script can set parameter interrupt_enabled to False when calling the ‘Controller.waitdone()` to skip the admin CQ interrupt checking.
The test scripts often need to get the dword0 of the CQE. So, Controller.waitdone() can return this value of the latest CQE from admin CQ. For example, the following script does not need to use the callback function to obtain CQE’s dword0.
def test_get_num_of_queue(nvme0):
cdw0 = nvme0.getfeatures(7).waitdone()
num_of_queue = (cdw0&0xffff) + 1
Controller object also provides the cid and latency (in us) of the latest admin command.
def test_latest_cid_latency(nvme0):
nvme0.format().waitdone()
logging.info("latest cid: %d" % nvme0.latest_cid)
logging.info("latest command latency: %d" % nvme0.latest_latency)
7.3 AER command
AER is a special admin command. The DUT will not return the CQE immediately after the system issues the AER command. Only when certain defined events occur will the DUT return CQE to CQ, along with the event information. So, AER commands are not applicable to timeout.
PyNVMe3’s script does not need to explicitly call Controller.waitdone() for AER commands, because host also do not know when AER’s CQE will be returned. Instead, when Controller.waitdone() reaps any AER’s CQE, PyNVMe3 will throw a warning to report the returned AER’s CQE, and send another AER command. After that, the Controller.waitdone() continues reap CQE from non-AER commands. So where an AER CQE is expected, the script can issue a helping admin command retrieve the AER CQE. Usually, we use nvme0.getfeatures(7).waitdone() for this purpose, as demonstrated below.
def test_sq_doorbell_invalid(nvme0):
cq = IOCQ(nvme0, 1, 10, PRP())
sq = IOSQ(nvme0, 1, 10, PRP(), cq=cq)
with pytest.warns(UserWarning, match="AER notification is triggered: 0x10100"):
sq.tail = 10
time.sleep(0.1)
nvme0.getfeatures(7).waitdone()
sq.delete()
cq.delete()
7.4 Common Methods
In addition to the admin commands, Controller objects also provide some commonly used methods, such as updating firmware, get the LBA format id, and etc. Because these APIs are not admin commands, so scripts do not need to call waitdone() for them. Here are some of these methods.
- Controller.downfw(): upgrade SSD firmware.
- Controller.reset(): start a Controller reset event, including the user-defined NVMe initialization process.
def test_admin_func(nvme0, nvme0n1): # download new firmware and reset conroller nvme0.downfw('path/firmware_image_file.bin') nvme0.reset() # reset the controller during IO with nvme0n1.ioworker(io_size=1, iops=1000, time=10): time.sleep(5) nvme0[0x14] = 0 nvme0.wait_csts(rdy=False) nvme0.reset() - Controller.get_lba_format(): get the format id of a specified data size and meta data size.
def test_get_lba_format(nvme0, nvme0n1): fid = nvme0.get_lba_format(data_size=512, meta_size=0, nsid=1) - Controller.supports(): determine if the DUT supports an admin command specified by its opcode (operation code defined in NVMe specification).
def test_controller_support_format(nvme0): if nvme0.supports(0x80): nvme0.format().waitdone() - Controller.timestamp() can get the timestamp of the DUT.
def test_timestamp(nvme0): logging.info("currect timestamp: %s" % nvme0.timestamp()) - Controller.iostat() can get the DUT’s current performance.
- PyNVMe3 provides convenient fixtures
id_ctrlandid_nsto easily get identify data:def test_identify(id_ctrl, id_ns): logging.info(id_ctrl.VID) logging.info(id_ctrl.SN) logging.info(id_ns.NSZE) logging.info(id_ns.NCAP)id_ctrlis Controller identify data, andid_nsis Namespace identify data. The field names of identify data are the same as the abbreviation names used in NVMe specification.
7.5 Command Timeout
PyNVMe3 can configure the timeout threshold of the command, which defaults to 10 seconds. After the command times out, the PyNVMe3 driver throws a warning and marks the error code as 07/ff in the CQE of this command.
Scripts can also change the timeout threshold of a specified command separately. For example, the format command usually takes a long time to complete, so the script can modify its timeout threshold. In the following example, Controller.timeout modifies the global timeout threshold defined in milliseconds, while API Controller.set_timeout_ms modifies the specified command’s timeout threshold.
def test_timeout_format(nvme0):
nvme0.timeout=10_000 #10s
nvme0.get_timeout_ms(opcode=0x80)
nvme0.set_timeout_ms(opcode=0x80, msec=30_000)
After each Controller’s reset, the timeout threshold of all commands will be restored to the default (e.g. 10 seconds).
7.6 cmdlog
When some issue happen, it would be helpful to exam the commands SQE and CQE in history. PyNVMe3 provides the cmdlog feature through API Controller.cmdlog(). It lists the command log of the admin queue. Similarity, Controller.cmdlog_merged() lists the command log of all queues, sorted in reverse order by SQE timestamp.
def test_command_log(nvme0):
for c in nvme0.cmdlog_merged(100): # cmdlog of all queues
logging.info(c)
for c in nvme0.cmdlog(10): # cmdlog of the admin queues
logging.info(c)
Here is an example of printed cmdlog. It contains the full SQE and CQE data, as well as timestamps for the SQE sent and CQE completed. We can find the same cmdlog in PyNVMe3 extension of VSCode.
2022-10-08 17:47:28.954447 [cmd000033: Identify, sqid: 0]
0x007e0006, 0x00000002, 0x00000000, 0x00000000
0x00000000, 0x00000000, 0x26cbe000, 0x00000000
0x00000000, 0x00000000, 0x00000000, 0x00000000
0x00000000, 0x00000000, 0x00000000, 0x00000000
2022-10-08 17:47:28.954568 [cpl: SUCCESS]
0x00000000, 0x00000000, 0x00000003, 0x0001007e
2022-10-08 17:47:28.954312 [cmd000034: Identify, sqid: 0]
0x007e0006, 0x00000001, 0x00000000, 0x00000000
0x00000000, 0x00000000, 0x26cbe000, 0x00000000
0x00000000, 0x00000000, 0x00000000, 0x00000000
0x00000000, 0x00000000, 0x00000000, 0x00000000
2022-10-08 17:47:28.954436 [cpl: SUCCESS]
0x00000000, 0x00000000, 0x00000002, 0x0001007e
2022-10-08 17:47:28.954082 [cmd000035: Identify, sqid: 0]
0x007e0006, 0x00000000, 0x00000000, 0x00000000
0x00000000, 0x00000000, 0x26cfe000, 0x00000000
0x00000000, 0x00000000, 0x00000001, 0x00000000
0x00000000, 0x00000000, 0x00000000, 0x00000000
2022-10-08 17:47:28.954231 [cpl: SUCCESS]
0x00000000, 0x00000000, 0x00000001, 0x0001007e
7.7 MDTS (Max Data Transfer Size)
NVMe drives can declare their maximum data transfer size (MDTS) supported. PyNVMe3 supports MDTS up to 2MB (the usual MDTS supported by NVMe SSD is 256K~1MB). When the size of the test data exceeds 2MB, the driver reports error. We can still use metamode to test larger MDTS. The script can get DUT’s MDTS value through Controller.mdts. In the following example, the script tries to send a read command whose data length exceeds MDTS, so the disk will return error.
def test_read_invalid_number_blocks(nvme0, nvme0n1, qpair):
mdts = nvme0.mdts//nvme0n1.sector_size
buf = Buffer((mdts+1)*nvme0n1.sector_size)
nvme0n1.read(qpair, buf, 0, mdts+1).waitdone()
7.8 Namespace-related Commands
PyNVMe3 supports namespace-related admin commands (e.g. Namespace Attachment and Management commands). Furthermore, PyNVMe3 provides some abstracted methods (e.g. ns_attach, ns_detach, ns_create and ns_delete) for your ease to use.
def test_namespace_detach_and_delete(nvme0, nvme0n1):
cntlid = nvme0.id_data(79, 78)
nvme0.ns_detach(1, cntlid)
nvme0.ns_delete(1)
7.9 Security Commands
PyNVMe3 also supports security_send and security_receive commands, and provides a complete TCG test suite.
7.10 Lazy Doorbell
PyNVMe3 supports different policies for updating admin SQ Doorbell when initializing the Admin queue. By default, PyNVMe3’s NVMe driver updates Doorbell immediately after issuing each admin command. However, when we set parameter lazy_doorbell to True, the driver updates Doorbell only when script calls Controller.waitdone(). For example, the following script, the Doorbell is updated only once for 3 successive getfeatures commands in nvme0.waitdone(3).
def test_ring_admin_queue_doorbell(nvme0):
def nvme_init_admin_lazy_doorbell(nvme0):
# 1. disable cc.en
nvme0[0x14] = 0
# 2. and wait csts.rdy to 0
nvme0.wait_csts(rdy=False)
# 3. set admin queue registers
if nvme0.init_adminq(lazy_doorbell=True) < 0:
raise NvmeEnumerateError("fail to init admin queue")
# 4. set register cc
nvme0[0x14] = 0x00460000
# 5. enable cc.en
nvme0[0x14] = 0x00460001
# 6. wait csts.rdy to 1
nvme0.wait_csts(rdy=True)
# 7. identify controller and all namespaces
identify_buf = Buffer(4096)
nvme0.identify(identify_buf).waitdone()
if nvme0.init_ns() < 0:
raise NvmeEnumerateError("retry init namespaces failed")
# 8. set/get num of queues
nvme0.setfeatures(0x7, cdw11=0xfffefffe, nsid=0).waitdone()
cdw0 = nvme0.getfeatures(0x7, nsid=0).waitdone()
nvme0.init_queues(cdw0)
# use the user defined nvme init function to reset the controller
nvme0.nvme_init_func = nvme_init_admin_lazy_doorbell
nvme0.reset()
nvme0.getfeatures(7)
nvme0.getfeatures(7)
nvme0.getfeatures(7)
nvme0.waitdone(3)
PyNVMe3 provides many APIs and parameters. We can find online help documents while editing scripts in VSCode. But you may need to add type hint to fixture names.
8. Namespace
When creating the Namespace object, PyNVMe3 associates it with a Controller object. When test is completed, script need to close the Namespace object explicitly.
nvme0n1 = Namespace(nvme0)
nvme0n1.close()
We prefer to use the fixture nvme0n1, so pytest will automatically close this Namespace object at the end of the test.
8.1 IO Commands
Through the Namespace object, the script can send various IO commands, which is similar to sending the admin commands with the Controller object. IO commands also have features like callback, timeout and etc. Different to admin commands, IO commands need a specified Qpair object to be sent. The command also needs to be reaped via API Qpair.waitdone(). Below is an example of writing data to LBA0.
def test_write(nvme0n1, qpair, buf)
nvme0n1.write(qpair, data_buf, 0).waitdone()
8.2 Methods
In addition to the IO commands, the Namespace class also provides some commonly used methods, such as Namespace.format(). These APIs are not asynchronous IO commands, so there is no need to call Qpair.waitdone() for them.
- format:
Controller.format()is an asynchronous admin command call, butNamespace.format()is a helping function to ease the format operation. It adjusts the timeout threshold of the format command, and wait for the completion of the format command. When your test case target is not Format command (e.g. format is only a step in your test case), you can always useNamespace.format()to format the DUT.def test_namespace_format(nvme0n1): nvme0n1.format() supports(),set_timeout_ms(),get_lba_format(): are the same as the counterpart inControllerclass.- PyNVMe3 supports the ZNS command set and provides a lot of test scripts.
id_nsis the fixture to retrieve fields in namespace Identify data. The field names are the same as the abbreviations used in the NVMe specification.Namespaceobject also provides some commonly used read-only properties, such asnsid,capacity,sector_size, and etc.
8.3 Data Verification
PyNVMe3 provides rich features and extremely high performance, but we pay more attention to the data consistency check. Data consistency is the most essential requirement of storage devices, so we should check it in every test cases if possible. PyNVMe3’s driver check data consistency transparently. For example, in this script:
def test_write_read(nvme0n1, qpair, buf, verify):
nvme0n1.write(qpair, buf, 0).waitdone()
nvme0n1.read(qpair, buf, 0).waitdone()
The script first writes LBA0 and then reads LBA0. After reading the LBA0 data, the PyNVMe3 driver will immediately check the consistency of the data, whether it is the same as the data just written. The only thing the script needs to do is add the verify fixture to the parameter list of the test function. We recommend that all test cases, except performance one, should enable data verification.
The verify fixture here has nothing to do with the Verify command defined in the NVMe specification. PyNVMe3 checks the data consistency through the CRC checksum, instead of comparing data bit by bit. When write command completes, a CRC (for a LBA) is calculated and wrote in DRAM. When read command completes, the CRC value of the data read is calculated again and compared with the CRC wrote in DRAM. Each LBA requires one byte to track CRC in huge-page memory. Taking 512-byte LBA as an example, a 4T disk needs about 8G of memory to store CRC, so we need to reserve enough huge-page memory through command line make setup when setting up the runtime environment.
During the initialization of the Namespace object, PyNVMe3 allocates memory for the CRC. If there is not enough memory, PyNVMe3 throws a warning message, and the data verification feature is turned off, but the test still can run without verification feature. Alternatively, script can limit the space of CRC verification by specify parameter nlba_verify when initializing the Namespace object. However, it is better to equip enough DRAM and huge-page memory to run formal tests with data verification feature enabled.
The data validation feature works on both ns.cmd and ioworker. Because read and write commands, it also works with other media commands, such as Trim, Format, and etc. The following script writes data in different ways, and finally reads the data with ioworker, and all data will be verified by CRC.
def test_verify(nvme0n1, verify):
# write data
nvme0n1.ioworker(io_size=8,
lba_random=False,
read_percentage=0,
qdepth=2,
io_count=1000).start().close()
nvme0n1.write(qpair, buf, 0).waitdone()
# verify data
nvme0n1.ioworker(io_size=8,
lba_random=False,
read_percentage=100,
io_count=1000).start().close()
In addition to CRC mechanism, we also need to construct special data pattern to detect potential problems. For example, if we keep writing all LBAs with same data, the CRC check cannot distinguish a LBA from another. Therefore, PyNVMe3 fills in the data (nsid, LBA) into the first 8-byte of each LBA. It is similar to Protect Information, but PyNVMe3 put some PI data into the data area, instead of metadata area.
Furthermore, suppose the script has been writing the same LBA, but host may get old data from history because of the wrong version of the data. Therefore, PyNVMe3 fills in a token into the last 8-byte of each LBA 8 (excluding metadata). This token is a number that globally increments from 0, ensuring that the data content is different for each IO in history.
So by default, the first 8-byte and last 8-byte of LBA are filled by PyNVMe3 driver. But the script still can turned off these behavior by calling Namespace.inject_write_buffer_disable(). Data verification with CRC can still work without injected LBA and token.
CRC data is stored in memory and the CRC value is lost after the test. The script can export CRC data to a specified file through API Namespace.save_crc(), and import CRC in later test through API Namespace.load_crc(). In this way, we can make the CRC data persistent, so as the data verification feature.
NVMe specification sends command and receives completion in asynchronous way. The order of IO is not guaranteed. It means, multiple write operations to the same LBA cannot guarantee the final data content. Similarity, the simultaneous read and write commands have no fixed order, so the data read is also not fixed to do meaningful verification. To avoid the problem, PyNVMe3 introduced LBA locks: before issuing each IO, all of its LBA are checked, and when any LBA is locked, we will not issue this IO. Only when all LBA of the IO are not locked, PyNVMe3 locks all of the LBAs before sending IO, and unlock all of the LBAs after the IO is completed. This ensures that only one IO is operating on one LBA at a time.
This LBA lock mechanism is only valid within the process, and the inter-process lock mechanism is too expensive, so it is not implemented. When there are 2 ioworkers reading and writing the same LBA, the data read is also not determined, so fake data miscompare may occur. The script can divide different LBA spaces for different ioworkers to avoid the problem. Or, as a special stress test, script should turn off data validation feature.
CRC and LBA locks are not only applicable for read and write commands, but also for all other commands that can access the storage medium, such as format/sanitize/trim/append, and etc. It is important to note that when a Trim/DSM command covers a very large LBA range, it is likely to be blocked for a long time due to check LBA locks. When implementing these kinds of tests, it is recommended to limit the nlb_verify when creating Namespace object.
9. Qpair
We send admin commands with Controller object, and send IO commands with Namespace object. But the difference is that IO commands require a Qpair object.
In PyNVMe3, we combine the submission queue SQ and the completion queue CQ into Qpair. The admin Qpair is embedded in the Controller object and is created in NVMe initialization process. IO Qpair is created through the Qpair class.
After the test is complete, the script must remove SQ and CQ by calling Qpair.delete(). The following example creates a qpair with queue depth 16 and deletes the qpair.
def test_qpair(nvme0):
qpair = Qpair(nvme0, depth=16)
qpair.delete()
If fixture qpair is used, PyNVMe3 automatically calls the delete function at the end of the test. It is our recommended way to use qpair.
def test_write_read(nvme0n1, qpair, buf):
nvme0n1.write(qpair, buf, 0).waitdone()
9.1 Qpair Creation
PyNVMe3 can specify the properties of SQ and CQ when creating the Qpair object, like interrupt enable, interrupt vector, priority, sqid, and etc.
Similar to the admin command, PyNVMe3 supports specifying a policy for updating Doorbell when initializing Qpair. By default, the PyNVMe3 driver updates Doorbell immediately after each IO command. However, when we set lazy_doorbell to True, the driver updates its Doorbell only when calling Qpair.waitdone(). For example, the following script, specifying the parameter lazy_doorbell=True of the qpair, sends 3 consecutive read commands. Doorbell is only updated once in qpair.waitdone(3).
def test_ioworker_with_qpair_performance(nvme0, nvme0n1, buf):
qpair = Qpair(nvme0, 1024, ien=False, lazy_doorbell=True)
nvme0n1.read(qpair, buf, 0)
nvme0n1.read(qpair, buf, 0)
nvme0n1.read(qpair, buf, 0)
qpair.waitdone(3)
qpair.delete()
When PyNVMe3 creates a Qpair, it requests memory for SQ and CQ queues. By default, the memory is located in system memory, but Qpair also supports Controller Memory Buffer.
9.2 Common Properties
Qpair object provides the following commonly used properties:
- latest_cid:the id of the IO command that was latest sent.
- latest_latency:the delay of IO command latest sent.
- prio:the priority of the queue.
- sqid:the sqid of the queue.
9.3 MSIx Interrupt
PyNVMe3 supports MSIx test. It implements a software interrupt controller, which allows scripts to configure and check interrupt signals on Qpair objects. When creating a Qpair object, scripts can enable the interrupts for CQ (enabled by default) and specify the interrupt vector. The script can use a set of interrupt-related APIs in Qpair:
qpair.msix_clear()clears all MSI-X interrupt signals on the qpair.qpair.msix_isset()checks if the interrupt exists on the Qpair.qpair.wait_msix()waits for the interrupt of the Qpair.qpair.msix_mask()masks the interrupt of the Qpair. All interrupt at this state will be hold.qpair.msix_unmask()unmasks the Qpair. If any interrupt is hold when the interrupt is marked, the new interrupt will be sent when the interrupt is unmasked.
Here’s an example to test the functionality of interrupt masking.
def test_interrupt_qpair_msix_mask(nvme0, nvme0n1, buf, qpair):
# create a pair of CQ/SQ and clear MSIx interrupt
qpair.msix_clear()
assert not qpair.msix_isset()
# send a read command
nvme0n1.read(qpair, buf, 0, 8)
time.sleep(0.1)
# check if the MSIx interrupt is set up
assert qpair.msix_isset()
qpair.waitdone()
# clear MSIx interrupt and mask it
qpair.msix_clear()
qpair.msix_mask()
assert not qpair.msix_isset()
# send a read command
nvme0n1.read(qpair, buf, 0, 8)
# check if the MSIx interrupt is NOT set up
time.sleep(0.2)
assert not qpair.msix_isset()
# unmask the MSIx interrupt
qpair.msix_unmask()
qpair.waitdone()
time.sleep(0.1)
# check if the MSIx interrupt is set up
assert qpair.msix_isset()
PyNVMe3 supports interrupt related testing, but PyNVMe3 does not rely on interrupts. PyNVMe3 checks CQ by calling Qpair.waitdone(), so it is the polling mode.
10. Subsystem
Subsystem object of PyNVMe3 mainly provides reset and power-related methods:
Subsystem.reset()implements the subsystem reset if it is supported by the DUT.Subsystem.poweron()powers on the DUT.Subsystem.poweroff()powers off the DUT.
By default, poweroff is implemented by the system’s S3 power mode and poweron is implemented by RTC. But S3/RTC is not always fully supported by motherboards. PyNVMe3 recommends Quarch PAM devices as the power controller of DUT, and supports it in scripts/pam.py. Developers can support their own power controller devices in a similar way of scripts/pam.py.
When creating Subsystem object, scripts can provide poweron and poweroff functions which control the power of the controller. Subsystem.poweroff() will indirectly call the provided poweroff function. Subsystem.poweron() will indirectly call the provided poweron function.
subsystem fixture uses Quarch PAM’s poweron and poweroff function is the power device is available on the system. Developer can expend this fixture with their own power controller. We can use the same way to dessert/assert the #PERST signal.
@pytest.fixture(scope="function")
def subsystem(nvme0, pam):
if pam.exists():
# use PAM to control power on off
ret = Subsystem(nvme0, pam.on, pam.off)
else:
# use S3 to control power on off
ret = Subsystem(nvme0)
return ret
In addition, the PyNVMe3 driver internally completes the device scanning and driver binding operations during the poweron and poweroff process, and the script only needs to call Controller.reset() after Subsystem.poweron() to initialize the DUT again. Users can follow the pam.py to adapt their own power controller without any change in driver. The test scripts use API Subsystem.poweron() and Subsystem.poweroff(), and they can work with different power controller.
Till now, we can use Namespace, Qpair and Buffer objects to send any IO commands, which is the regular way called ns.cmd IO mode. For higher performance, we can use IOWorker. Let’s move ahead.
11. IOWorker
With ioworker, we can hit greater IO pressure than fio, and meanwhile achieve a variety of test targets and features, such as SGL, ZNS, etc. PyNVMe3 can also define other actions in scripts while ioworker is running, such as power cycle, reset, and commands. This allows the script to enable more complex test scenarios. Each ioworker will create a separate child process to send and receive IO, and will create its own qpair, which will be deleted after the ioworker is completed.
In order to make better use of IOWorker, we will introduce the parameters of IOWorker one by one with pieces of demonstrated examples. But the test script does not need to define every parameter one by one, because the default values are reasonable for most of the time. IOWorker has many parameters, so scripts have to use keyword to define each parameter.
11.1 Parameters
io_size
io_size defines the size of each IO, which is in LBA units, and the default is 8 LBA. It can be a fixed size, or a list of multiple sizes. If the proportion of the sizes is not evenly distributed, we can the percentage in the dictionary form.
The script below demonstrates 3 cases: 4k random read; 4K/8k/128k uniform mixed random read; 50% 4K random read, 25% 8K random read, and 25% 128K random read.
def test_ioworker_io_size(nvme0n1):
nvme0n1.ioworker(io_size=8,
time=5).start().close()
nvme0n1.ioworker(io_size=[8, 16, 256],
time=5).start().close()
nvme0n1.ioworker(io_size={8:50, 16:25, 256:25},
time=5).start().close()
time
time controls the running time of the ioworker in seconds. Below is an example of an ioworker running for 5 seconds.
def test_ioworker_time(nvme0n1):
nvme0n1.ioworker(io_size=8,
time=5).start().close()
io_count
io_count specify the number of IOs to send in the ioworker. The default value is 0, which means unlimited. Either io_count or time has to be specified. When both are specified, the ioworker ends when either limit is met. The following example demonstrates sending 10,000 IO.
def test_ioworker_io_count(nvme0n1):
nvme0n1.ioworker(io_size=8,
io_count=10000).start().close()
lba_count
lba_count parameter in the ioworker function is used to specify the total number of Logical Block Addresses (LBAs) that should be processed before concluding the ioworker’s operation. This parameter is particularly useful when the io_size parameter is set to define multiple sizes, allowing for more precise control over the ioworker’s execution based on the number of LBAs rather than io_count.
lba_random
lba_random specifies the percentage of random IO, the default is True, which means 100% random LBA. The following example demonstrates a sequential IO and a 50%-random IO.
def test_ioworker_lba_random(nvme0n1):
nvme0n1.ioworker(lba_random=False,
time=5).start().close()
nvme0n1.ioworker(lba_random=50,
time=5).start().close()
lba_start
lba_start specifies the LBA address of the first command. The default value is 0.
lba_step
lba_step can only be used in sequential IO, where the starting LBA of IO will be controlled by lba_step. The size of the lba_step, like the io_size, is in LBA unit. The following example demonstrates an IO size of 4k sequential read, with a 4K-gap between each IO.
def test_ioworker_lba_step(nvme0n1):
nvme0n1.ioworker(io_size=8,
lba_random=False,
lba_step=16,
time=5).start().close()
With lba_step, ioworker can also decrease the LBA address of the IO. Script can set it to a negative number. The following example demonstrates reading in reverse order, where ioworker sends read commands on LBA 10, 9, 8, 7, 6, 5, 4, 3, 2, 1.
def test_ioworker_lba_step(nvme0n1):
nvme0n1.ioworker(lba_random=False,
io_size=1,
lba_start=10,
lba_step=-1,
io_count=10).start().close()
When the lba_step is set to 0, ioworker can repeatedly read and write to the specified LBA.
def test_ioworker_lba_step(nvme0n1):
nvme0n1.ioworker(lba_random=False,
lba_start=100,
lba_step=0,
time=5).start().close()
read_percentage
read_percentage Specify the ratio of reads and writes, 0 means all write, 100 means all read. The default is 100. The following is an example of 50% each.
def test_ioworker_read_percentage(nvme0n1):
nvme0n1.ioworker(read_percentage=50,
time=5).start().close()
op_percentage
op_percentage can specify the opcode of the commands, not limited on read and write, sent in the ioworker. When both op_percentage and read_percentage exist, the op_percentage prevails. The following is an example of 40% read command, 30% write command, and 30% trim command mixed IO.
def test_ioworker_op_percentage(nvme0n1):
nvme0n1.ioworker(op_percentage={2: 40, 9: 30, 1: 30},
time=5).start().close()
sgl_percentage
sgl_percentage specifies the percentage of IO using SGL. 0 means only PRP and 100 means only SGL. The default value is 0. The following example demonstrates setting the commands issued by ioworker to use 50% PRP and 50% SGL.
def test_ioworker_sgl_percentage(nvme0n1):
nvme0n1.ioworker(sgl_percentage=50,
time=5).start().close()
qdepth
qdepth specifies the queue depth of the Qpair object created by the ioworker. The default value is 63. Below is an example of an IO queue depth of 127 (Q’s size is 128) used in ioworker.
def test_ioworker_qdepth(nvme0n1):
nvme0n1.ioworker(qdepth=127,
time=5).start().close()
qprio
qprio specifies the priority of the SQ created by the ioworker. The default value is 0. This parameter is only valid when the arbitration mechanism is selected as weighted round robin with urgent priority (WRR).
def test_ioworker_qprio(nvme0n1):
nvme0n1.ioworker(qprio=0,
time=5).start().close()
region_start
IOWorker sends IO in the specified LBA region, from region_start to region_end. Below is an example of sending IO starting from an LBA 0x10.
def test_ioworker_region_start(nvme0n1):
nvme0n1.ioworker(region_start=0x10,
lba_random=True,
time=5).start().close()
region_end
IOWorker sends IO in the specified LBA region, from region_start to region_end. region_end is not included in the region. Its default value is the max_lba of the drive. When send IO with sequential LBA, and neither time nor io_count specified, ioworker send IO from region_start to region_end by one pass. Below is an example of sending IO from LBA 0x10 to 0xff.
def test_ioworker_region_end(nvme0n1):
nvme0n1.ioworker(region_start=0x10,
region_end=0x100,
time=5).start().close()
iops
In order to construct test scenarios under different pressures, the iops parameter in ioworker can specify the maximum IOPS. Then ioworker limits the speed at which IOs are sent. The default value is 0, which means unlimited. Below is an example that specifies an IOPS pressure of 12345 IO per second.
def test_ioworker_iops(nvme0n1):
nvme0n1.ioworker(iops=12345,
time=5).start().close()
io_flags
io_flags specifies the 16 bits of dword12 of io commands issued in the ioworker. The default value is 0. The following is an example of sending write command with FUA bit enabled.
def test_ioworker_io_flags(nvme0n1):
nvme0n1.ioworker(io_flags=0x4000,
read_percentage=0,
time=5).start().close()
distribution
distribution parameter divides the whole LBA space into 100 parts, and distribute all 10,000 parts of IO into 100 parts of LBA space. The list indicates how to allocate 10,000 IOs to these 100 different parts. This parameter can be used to implement the JEDEC endurance workload as below: 1000 IOs are allocated in each of the first 5 1% intervals, that is, the first 5% interval contains half of the IO; Each of the 15 1% intervals of 5%-20% allocates 200 IOs, that is, this 15% LBA space contains 30% of IO; The last 80% of the interval contains the remaining 20%.
def test_ioworker_jedec_workload(nvme0n1):
distribution = [1000]*5 + [200]*15 + [25]*80
iosz_distribution = {1: 4,
2: 1,
3: 1,
4: 1,
5: 1,
6: 1,
7: 1,
8: 67,
16: 10,
32: 7,
64: 3,
128: 3}
nvme0n1.ioworker(io_size=iosz_distribution,
lba_random=True,
qdepth=128,
distribution=distribution,
read_percentage=0,
ptype=0xbeef, pvalue=100,
time=1).start().close()
ptype and pvalue
The same as ptype and pvalue of Buffer objects, ioworker also can specify data pattern with these two parameter. The default pattern in ioworker is a total random buffer that cannot be compressed.
def test_ioworker_pvalue(nvme0n1):
nvme0n1.ioworker(ptype=32,
pvalue=0x5a5a5a5a,
read_percentage=0,
time=5).start().close()
io_sequence
io_sequence can specify the starting LBA, the number of LBAs, the opcode of the command, and the send timestamp (in us) for each IO sent by ioworker. io_sequence is a list containing commands information, and one command information is (slba, nlb, opcode, time_sent_us). The following is an example of sending read and write commands via ioworker. With parameters, the script can send the specified IO at the specified time through ioworker.
def test_ioworker_pvalue(nvme0n1):
nvme0n1.ioworker(io_sequence=[(0, 1, 2, 0),
(0, 1, 1, 1000000)],
ptype=0, pvalue=0).start().close()
slow_latency
slow_latency is in unit of microseconds (us). When the IO latency is greater than this parameter, ioworker prints a debug message and throws a warning. The default is 1 second.
def test_ioworker_slow_latency(nvme0n1):
nvme0n1.ioworker(io_size=128,
slow_latency=2000_000,
time=5).start().close()
exit_on_error
When any IO command fails, the ioworker exits immediately. If you want to continue running ioworker when any IO command fails, you need to specify this parameter exit_on_error to False.
def test_ioworker_exit_on_error(nvme0n1):
nvme0n1.ioworker(exit_on_error=True,
time=5).start().close()
cpu_id
The cpu_id parameter in ioworker is designed to distribute the workload across different CPU cores. To achieve optimal performance and latency, it is assumed that each ioworker utilizes 100% of a single CPU core’s resources. However, in practice, multiple ioworkers may sometimes be allocated to the same CPU core. When this happens, the combined performance of these ioworkers is nearly the same as that of a single ioworker. This outcome is not desirable when using multiple ioworkers, so the cpu_id parameter is used to enforce the allocation of different ioworkers to separate CPU cores.
For example, in a 4K random read performance test, one ioworker can achieve 1M IOPS, and two ioworkers can achieve 2M IOPS. However, if they are accidentally allocated to the same CPU core, the two ioworkers still only achieve 1M IOPS. By using the cpu_id parameter, we can avoid this situation and ensure that each ioworker is assigned to a different CPU core, thus achieving the expected performance increase.
def test_performance(nvme0, nvme0n1):
qcount = 1
iok = 4
qdepth = 128
random = True
readp = 100
iosize = iok*1024//nvme0n1.sector_size
l = []
for i in range(qcount):
a = nvme0n1.ioworker(io_size=iosize,
lba_align=iosize,
lba_random=random,
cpu_id=i+1,
qdepth=qdepth-1,
read_percentage=readp,
time=10).start()
l.append(a)
io_total = 0
for a in l:
r = a.close()
logging.debug(r)
io_total += (r.io_count_read+r.io_count_nonread)
logging.info("Q %d IOPS: %.3fK, %dMB/s" % (qcount, io_total/10000, io_total/10000*iok))
11.2 Output Parameters
output_io_per_second
Save the number of IOs per second in the form of a list. Default value: None, no data is collected. Below is an example of collecting IOPS per second in a io_per_second list.
def test_ioworker_output_io_per_second(nvme0n1):
io_per_second = []
nvme0n1.ioworker(output_io_per_second=io_per_second,
time=5).start().close()
logging.info(io_per_second)
output_percentile_latency
IO latency is important on both Client SSD and Enterprise SSD. IOWorker use parameter output_percentile_latency to collect latency information of all IO. ioworker can collect IO latency on different percentages in the form of a dictionary. The dictionary key is a percentage and the value is the delay in microseconds (us). Default value: None, no data is collected. The following example demonstrates the latency of 99%, 99.9%, 99.999% IO.
def test_ioworker_output_percentile_latency(nvme0n1):
percentile_latency = dict.fromkeys([99, 99.9, 99.999])
nvme0n1.ioworker(output_percentile_latency=percentile_latency,
time=5).start().close()
logging.info(percentile_latency)
After specifying this parameter, we can obtain the number of IOs on each latency time time point from latency_distribution in returned object. With these data, scripts can draw distribution graph as below.
output_percentile_latency_opcode
IOWorker can tracked the specified opcode commands latency. Default value: None, which tracks the latency of all opcodes. The following example demonstrates only tracking the latency of DSM commands in returned output_percentile_latency.
def test_ioworker_output_percentile_latency_opcode(nvme0n1):
percentile_latency = dict.fromkeys([99, 99.9, 99.999])
nvme0n1.ioworker(op_percentage={2: 40, 9: 30, 1: 30},
output_percentile_latency=percentile_latency,
output_percentile_latency_opcode=9,
time=5).start().close()
logging.info(percentile_latency)
output_cmdlog_list
This parameter collects information about commands that ioworker latest sent and reaped. The information for each command includes the starting LBA, the number of LBAs, the command operator, the send timestamp, the reap timestamp, the return status. These information of commands are recorded in tuples (slba, nlb, opcode, time_sent_us, time_cplt_us, status). The default value is None, which does not collect data. The following scripts can give latest 1000 commands’ information before poweroff happen.
def test_power_cycle_dirty(nvme0, nvme0n1, subsystem):
cmdlog_list = [None]*1000
# 128K random write
with nvme0n1.ioworker(io_size=256,
lba_align=256,
lba_random=True,
read_percentage=30,
slow_latency=2_000_000,
time=15,
qdepth=63,
output_cmdlog_list=cmdlog_list):
# sudden power loss before the ioworker end
time.sleep(5)
subsystem.poweroff()
# power on and reset controller
time.sleep(5)
start = time.time()
subsystem.poweron()
nvme0.reset()
logging.info(cmdlog_list)
cmdlog_error_only
When cmdlog_error_only is True, ioworker only collects the information of error commands into output_cmdlog_list.
11.3 Return Values
IOWorker.close() returns after all IO sent and reaped by ioworker, and it gives a structure includes these parameters:
io_count_read: Counts the read commands executed by the ioworker.io_count_nonread: Tally of non-read commands executed by the ioworker.mseconds: Duration of the ioworker operation in milliseconds.latency_max_us: Maximum command latency, measured in microseconds.error: Error code recorded in case of an IO error.error_cmd: Submission Queue Entry of the command causing an IO error.error_cpl: Completion Queue Entry of the command causing an IO error.cpu_usage: CPU usage during the test to assess host CPU load.latency_average_us: Average latency of all IO commands, in microseconds.latency_distribution: Latency count at each time point up to 1,000,000 microseconds.io_count_write: Number of write commands executed by the ioworker.lba_count_read: Number of LBAs read during the operation.lba_count_nonread: Count of LBAs processed in non-read operations.lba_count_write: Total LBAs written by the ioworker.
Here’s a normal ioworker returned object:
'io_count_read': 10266880,
'io_count_nonread': 0,
'mseconds': 10001,
'latency_max_us': 296,
'error': 0,
'error_cmd': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'error_cpl': [0, 0, 0, 0],
'cpu_usage': 0.8465153484651535,
'latency_average_us': 60,
'test_start_sec': 1669363788,
'test_start_nsec': 314956299,
'latency_distribution': None,
'io_count_write': 0
And this is the return object with error:
'io_count_read': 163,
'io_count_nonread': 0,
'mseconds': 2,
'latency_max_us': 791,
'error': 641,
'error_cmd': [3735554, 1, 0, 0, 0, 0, 400643072, 4, 0, 0, 5, 0, 0, 0, 0, 0],
'error_cpl': [0, 0, 131121, 3305242681],
'cpu_usage': 0.0,
'latency_average_us': 304,
'test_start_sec': 1669364412,
'test_start_nsec': 822867651,
'latency_distribution': None,
'io_count_write': 0
Here is the ioworker error codes and descriptions
| Error Code | Error Name | Description |
|---|---|---|
| 0 | Success | Indicates that no error occurred during the operation. |
| -1 | Init Fail in Pyx | Initialization failed in the underlying Pyx library or hardware abstraction. |
| -2 | IO Size is Larger than MDTS | The I/O request size exceeds the Maximum Data Transfer Size (MDTS) limit. |
| -3 | IO Timeout | The I/O operation did not complete within the expected time limit. |
| -4 | IOWorker Timeout | The ioworker process or thread exceeded its execution time limit. |
| -5 | Buffer Pool Alloc Fail | Failed to allocate memory from the buffer pool for the I/O operation. |
| -6 | IO Cmd Error | An error occurred during the execution of an NVMe I/O command. |
| -7 | Sudden Terminated | The ioworker was unexpectedly terminated before completing its operation. |
| -8 | Slow IO | The I/O operation completed but took significantly longer than expected. |
| -9 | Create Qpair Fail | Failed to create a queue pair (Submission Queue or Completion Queue). |
| -10 | Illegal Sector Size | The sector size specified for the operation is invalid or unsupported. |
11.4 Examples
- 4K Full Disk Sequential Reading:
def test_ioworker_full_disk(nvme0n1): ns_size = nvme0n1.id_data(7, 0) nvme0n1.ioworker(lba_random=False, io_size=8, read_percentage=100, time=100).start().close() - 4K full disk random write:
def test_ioworker_qpair(nvme0n1): nvme0n1.ioworker(lba_random=True, io_size=8, read_percentage=0, time=3600).start().close() - Inject reset event during the IO:
def test_reset_controller_reset_ioworker(nvme0, nvme0n1): # issue controller reset while ioworker is running with nvme0n1.ioworker(io_size=8, time=10): time.sleep(5) nvme0.reset()
11.5 Compare with FIO
Both FIO and IOWorker provide many parameters. This table can help us to port FIO tests to PyNVMe3/IOWorker.
| fio parameter | ioworker parameter | Description |
|---|---|---|
bs |
io_size |
Sets the block size for I/O operations. ioworker can provide a single block size or specify multiple sizes through a list or dict. |
ba |
lba_align |
The LBA alignment for I/O. By default, fio aligns with the bs value, whereas ioworker defaults to 1. |
rwmixread |
read_percentage |
Specifies the percentage allocation of read-write mix. |
percentage_random |
lba_random |
Defines the percentage of random versus sequential operations. |
runtime |
time |
Defines the duration of the test run. |
size |
region_start, region_end |
Defines the size or range of the test area. PyNVMe3 can define the start and end LBA addresses of a single continuous region or specify multiple discrete areas through a list parameter. |
iodepth |
qdepth |
Sets the queue depth. |
buffer_pattern |
ptype, pvalue |
Sets the data pattern for the I/O buffer. ioworker fills the data buffer with the specified pattern upon initialization. |
rate_iops |
iops |
Limits the number of I/O operations per second. |
verify |
fio uses verify to check data integrity. PyNVMe3, by default, verifies the data consistency of each LBA with CRC after each read operation. |
|
ioengine |
fio typically selects libaio, while ioworker directly utilizes the higher performance SPDK driver. | |
norandommap |
fio uses norandommap for entirely random reads and writes. PyNVMe3 behaves completely randomly and uses LBA locks to ensure asynchronous I/O mutuality on LBAs, allowing data consistency checks to be performed in most cases. |
|
lba_step |
Specifies the step increment for sequential read/write LBAs. Normally, sequential reads/writes will cover all LBAs continuously, without gaps. However, lba_step can produce sequences with LBA gaps or overlaps. Specifying a negative lba_step can generate sequences with decreasing starting LBA addresses. |
|
op_percentage |
While fio supports only three operations (read, write, trim), ioworker can specify any type of I/O command and its percentage by specifying opcode. |
|
sgl_percentage |
ioworker can use PRP or SGL to represent the address range of data buffers. This parameter specifies the percentage of I/Os using SGL. | |
io_flags |
Specifies the high 16 bits of the 12th command word for all I/Os, including flags like FUA. | |
qprio |
Specifies the queue priority to implement scenarios with Weighted Round Robin arbitration. |
11.6 Performance
When an ioworker‘s return value’s cpu_usage is close to or exceeds 0.9, it indicates that the performance bottleneck is on the host side. To achieve higher performance in this scenario, it’s recommended to employ additional ioworkers. By specifying different cpu_id parameters, different ioworkers can be distributed across various CPUs. Here’s an example illustrating this approach:
l = []
for i in range(qcount):
a = nvme0n1.ioworker(io_size=iosize,
lba_align=iosize,
region_end=region_end,
lba_random=random,
cpu_id=i+1,
qdepth=qdepth-1,
read_percentage=readp,
time=10).start()
l.append(a)
io_total = 0
for a in l:
r = a.close()
logging.info(r)
io_total += (r.io_count_read + r.io_count_nonread)
logging.info("Q %d IOPS: %.3fK, %dMB/s" % (qcount, io_total/10000, io_total/10000 * iok))
In this example, multiple ioworkers are created within a loop, each with a unique cpu_id. This ensures that each ioworker operates on a different CPU, thereby distributing the workload and potentially enhancing overall performance. After starting all ioworkers, their results are aggregated to calculate total I/O operations and performance metrics, such as IOPS and throughput, are logged.
It is often sufficient to use a single ioworker to achieve adequate performance. However, when testing PCIe Gen5 NVMe drives’ random read performance, it is advisable to utilize 2-4 ioworkers. The need for additional ioworkers increases further if verify feature is enabled during read operations.
12. metamode IO
PyNVMe3 provides high-performance NVMe drivers for SSD product testing. But high performance can also lead to a lack of flexibility to test every detail defined in the NVMe specification. In order to cover more details, PyNVMe3 provides metamode to send and receive IO.
Through metamode, the script can directly create IOSQ/IOCQ on system buffer, write SQE into IOSQ, and read CQE from IOCQ.
Metamode requires script development engineers to have a certain understanding of the NVMe specification. But on the other head, metamode also help engineers better understand the command processing flow of NVMe.
The following simple example shows how to write test scripts using metamode following the command processing flow defined by the NVMe specification.
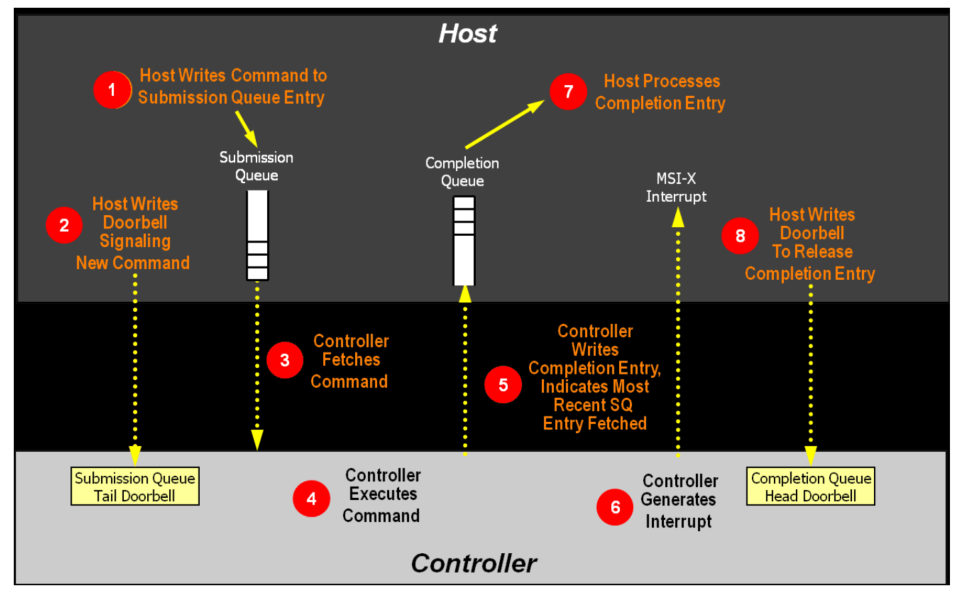
Step1: Host writes command to SQ Entry
cmd_read = SQE(2, 1)
cmd_read.cid = 0
buf = PRP(4096)
cmd_read.prp1 = buf
sq[0] = cmd_read
Step2: The host updates the SQ tail doorbell register. Notify SSD that a new command is pending.
sq.tail = 1
Step3: DUT get SQE from IOSQ
Step4: DUT processing SQE
Step5: DUT writes CQE to IOCQ
Step6: DUT sends interrupt (optional)
step3-6 are all handled by the DUT.
Step7: Host processes Completion entry
cq.wait_pbit(cq.head, 1)
Step8: The host writes the CQ head doorbell to release the completion entry
cq.head = 1
The complete test script is as follows:
def test_metamode_read_command(nvme0):
# Create an IOCQ and IOSQ
cq = IOCQ(nvme0, 1, 10, PRP(10*16))
sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq)
# Step1: Host writes command to SQ Entry
cmd_read = SQE(2, 1)
cmd_read.cid = 0
buf = PRP(4096)
cmd_read.prp1 = buf
sq[0] = cmd_read
# Step2: The host updates the SQ tail doorbell register. Notify SSD that a new command is pending.
sq.tail = 1
# Step7: Host processes Completion entry
cq.wait_pbit(cq.head, 1)
# Step8: The host writes the CQ head doorbell to release the completion entry
cq.head = 1
# print first CQE's status field
logging.info(cq[0].status)
The above script is a little bit more complex, but you can control every detail of the test. metamode also encapsulates a read/write interface to facilitate scripts to send common IOs in metamode. The following test script re-implements the same IO process as the example above.
def test_metamode_example(nvme0):
# Create an IOCQ and IOSQ
cq = IOCQ(nvme0, 1, 10, PRP(10*16))
sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq)
# Step1: Host writes command to SQ Entry
sq.read(cid=0, nsid=1, lba=0, lba_count=1, prp1=PRP(4096))
# Step2: The host updates the SQ tail doorbell register. Notify SSD that a new command is pending.
sq.tail = 1
# Step7: Host processes Completion entry
cq.waitdone(1)
# Step8: The host writes the CQ head doorbell to release the completion entry
cq.head = 1
# print first CQE's status field
logging.info(cq[0].status)
In addition to define the host command processing flow, metamode can also configure any parameters in the IO command. Here are a few examples of scenarios to help you better understand metamode’s capability.
12.1 Customized PRP List
def test_prp_valid_offset_in_prplist(nvme0):
# Create an IOCQ and IOSQ
cq = IOCQ(nvme0, 1, 10, PRP(10*16))
sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq)
# Construct PRP1, set offset to 0x10
buf = PRP(ptype=32, pvalue=0xffffffff)
buf.offset = 0x10
buf.size -= 0x10
# Construct PRP list, and set offset to 0x20
prp_list = PRPList()
prp_list.offset = 0x20
prp_list.size -= 0x20
# Fill 8 PRP entries into the PRP list
for i in range(8):
prp_list[i] = PRP(ptype=32, pvalue=0xffffffff)
# Construct a read command with the above PRP and PRP list
cmd = SQE(2, 1)
cmd.prp1 = buf
cmd.prp2 = prp_list
# Set the cdw12 of the command to 1
cmd[12] = 1
# Write command to SQ Entry, update SQ tail doorbell
sq[0] = cmd
sq.tail = 1
# Wait for the CQ pbit to flip
cq.wait_pbit(0, 1)
# Updated CQ head doorbell
cq.head = 1
12.2 Asymmetric SQ and CQ
def test_multi_sq_and_single_cq(nvme0):
# Create 3 IOSQ, and mapping to a single IOCQ
cq = IOCQ(nvme0, 1, 10, PRP(10*16))
sq1 = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq)
sq2 = IOSQ(nvme0, 2, 10, PRP(10*64), cq=cq)
sq3 = IOSQ(nvme0, 3, 10, PRP(10*64), cq=cq)
# Construct a write command
cmd_write = SQE(1, 1)
cmd_write.cid = 1
cmd_write[12] = 1<<30
# Set buffer of the write command
buf2 = PRP(4096)
buf2[10:21] = b'hello world'
cmd_write.prp1 = buf2
# Construct a read command
cmd_read1 = SQE(2, 1)
buf1 = PRP(4096)
cmd_read1.prp1 = buf1
cmd_read1.cid = 2
# Construct another read command
cmd_read2 = SQE(2, 1)
buf3 = PRP(4096)
cmd_read2.prp1 = buf3
cmd_read2.cid = 3
# place the commands into the SQs
sq1[0] = cmd_write
sq2[0] = cmd_read1
sq3[0] = cmd_read2
# Update SQ1 Tail doorbell to 1
sq1.tail = 1
# Wait for the Phase Tag of the head of CQE to be 1
cq.wait_pbit(cq.head, 1)
# Update CQ Head doorbell to 1
cq.head = 1
# Update SQ2 Tail doorbell to 1, and wait for the command completion
sq2.tail = 1
cq.wait_pbit(cq.head, 1)
# Update CQ Head doorbell to 2
cq.head = 2
# Update SQ3 Tail doorbell to 1
sq3.tail = 1
cq.wait_pbit(cq.head, 1)
# update CQ Head doorbell to 3
cq.head = 3
# Get the command represented by the first entry in CQ to complete the whole and command id
logging.info(cq[0].status)
logging.info(cq[0].cid)
12.3 Inject conflict cid error
Normally, NVMe device driver assign CID to each command, so the cid is always correct, and test script has no way to inject errors. With metamode provided by PyNVMe3, scripts can specify CID in each command. So, we can deliberately send multiple commands with the same CID to exam the DUT’s error handling.
def test_same_cid(nvme0):
# Create IOCQ/IOSQ with the depth of 10
cq = IOCQ(nvme0, 1, 10, PRP(10*16))
sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq)
# Write two commands, and both cid are 1
cmd_read1 = SQE(2, 1)
buf1 = PRP(4096)
cmd_read1.prp1 = buf1
cmd_read1.cid = 1
cmd_read2 = SQE(2, 1)
buf2 = PRP(4096)
cmd_read2.prp1 = buf2
cmd_read2.cid = 1
# fill two SQE to SQ
sq[0] = cmd_read1
sq[1] = cmd_read2
# Updated SQ tail doorbell
sq.tail = 2
# Wait for the Phase Tag in entry 1 in CQ to be 1
cq.wait_pbit(1, 1)
# Update CQ Head doorbell to 1
cq.head = 2
# Get the command completion status and command id indicated by the second entry in CQ
logging.info(cq[1].status)
logging.info(cq[1].cid)
12.4 Inject invalid doorbell errors
def test_aer_doorbell_out_of_range(nvme0, buf):
# Send an AER command
nvme0.aer()
# Create a pair of CQ and SQ with a queue depth of 16
cq = IOCQ(nvme0, 4, 16, PRP(16*16))
sq = IOSQ(nvme0, 4, 16, PRP(16*64), cq.id)
# Update the SQ tail to 20, which exceeds the SQ depth
with pytest.warns(UserWarning, match="AER notification is triggered: 0x10100"):
sq.tail = 20
time.sleep(0.1)
nvme0.getfeatures(7).waitdone()
# Send get logpage command to clear asynchronous events
nvme0.getlogpage(1, buf, 512).waitdone()
#Delete SQ and CQ
sq.delete()
cq.delete()
By sending IO through metamode, scripts can directly read and write various metadata structures defined by the NVMe protocol, including: IOSQ, IOCQ, SQE, CQE, doorbell, PRP, PRPList, and various SGLs. The script creates and accesses the shared memory with the NVMe DUT directly, without any restrictions form OS or driver.
13. SRIOV Testing
PyNVMe3 provides comprehensive support for testing the Single Root Input/Output Virtualization (SRIOV) feature. SRIOV allows a device, such as a NVMe SSD, to separate access to its resources among various PCIe hardware functions. These hardware functions consist of one Physical Function (PF) and one or more Virtual Functions (VF).
In terms of testing, PyNVMe3 facilitates the creation of VFs and namespaces, and the attachment of namespaces to VFs. This is done through a demo script file located in the scripts/features folder. It’s important to note that before any SRIOV testing can be performed, virtual functions need to be enabled in the Device Under Test (DUT).
make setup numvfs=5
make test TESTS=./scripts/features/sriov_test.py pciaddr=0000:01:00.0
PyNVMe3’s testing capabilities extend to executing tests on a single VF or multiple VFs simultaneously. This is carried out by using existing scripts and specifying the id of the VF to be tested. Before runing the tests on VFs, we shall create namespaces, attach them to VFs, and make all VFs online.
make setup numvfs=5
make test TESTS=./scripts/test_utilities.py::test_create_ns_attach_vf
make test TESTS=./scripts/test_utilities.py::test_vf_init
Then we can run multiple tests in different Terminals:
make test TESTS=./scripts/benchmark/ioworker_stress.py pciaddr=0000:01:00.0 vfid=1 nsid=1
make test TESTS=./scripts/benchmark/ioworker_stress.py pciaddr=0000:01:00.0 vfid=2 nsid=3
make test TESTS=./scripts/conformance/02_nvm pciaddr=0000:01:00.0 vfid=4 nsid=4
All these features make PyNVMe3 a powerful tool for validating and exploring the capabilities of SRIOV.
14. Desktop Test Platform
The PyNVMe3 Desktop Test Platform is a high-performance, cost-effective testing environment designed for NVMe SSD validation. It provides a flexible solution for developers, enabling comprehensive protocol, performance, power management, and out-of-band (OOB) management interface testing. It is fully integrated with PyNVMe3.
We do not sell this desktop test platform. Instead, users can purchase all necessary hardware from the market, including:
- Desktop PC Motherboard
- PMU2 Interposer (Email Inquiry)
- Total Phase Aardvark I2C Host Adapter (Product Page)
This approach provides users with the flexibility to build a cost-effective and customizable testing environment.
14.1 Motherboard (Informative)
The desktop PC motherboard is the foundation of the PyNVMe3 Desktop Test Platform, providing PCIe connectivity for NVMe SSD testing. A suitable motherboard should meet the following criteria:
- PCIe Gen5 support to ensure compatibility with the latest high-speed NVMe SSDs
- Stable power delivery for accurate power consumption and performance measurements
- Proper ventilation to maintain system stability during extended testing
One recommended motherboard for the PyNVMe3 Desktop Test Platform is:
- Model: Asus X670E ROG Crosshair Gene
- CPU: AMD Ryzen 5 7600X
- Memory: DDR5 16GB × 2
- System drive: 2.5-inch SATA SSD (running Ubuntu OS)
This configuration offers strong single-core performance, PCIe Gen5 support, and DDR5 compatibility, making it well-suited for enterprise NVMe SSD testing.
14.2 PMU2: Power Management Unit
PMU2 is a power management and monitoring unit designed for enterprise NVMe SSD testing. It provides precise power control, real-time power consumption monitoring, and support for out-of-band (OOB) management interface testing. It is compatible with PCIe Gen5 and supports both U.2 and M.2 SSDs, making it a versatile solution for SSD validation.
| Category | Features |
|---|---|
| PCIe | Supports PCIe Gen5 |
| Supports both U.2 and M.2 SSDs | |
| Future support planned for E1.S SSDs | |
| Power | Controls DUT power on/off |
| Monitors DUT power consumption | |
| OOB | Enables NVMe-MI OOB testing with Aardvark |
| Independent AUX power control for enhanced OOB tests | |
| Built-in voltage level shifting on the M.2 version |

PMU2 is easy to set up and integrates seamlessly with the PyNVMe3 framework.
- Insert the DUT into the PMU2 test slot.
- Insert PMU2 into the motherboard.
- Connect PMU2 to the desktop test platform via the Type-C USB port (white USB cable in the image above).
- Connect PMU2 to the Total Phase I2C host adapter and then to the desktop test platform (black USB cable in the image above).
- Power on the desktop test platform.
PMU2 will be automatically recognized and is ready for PyNVMe3 tests.
14.3 Aardvark I2C Host Adapter
The Aardvark I2C/SPI Host Adapter from Total Phase is a USB-to-I2C adapter that serves as the physical layer device for NVMe-MI out-of-band (OOB) testing over I2C/SMBus. Unlike traditional setups that rely on a baseboard management controller (BMC) in server environments, PyNVMe3 leverages this compact adapter to enable MI testing on standard desktop platforms. This eliminates the need for expensive server-grade infrastructure while maintaining full testing capabilities.
The Aardvark adapter plays a crucial role in NVMe-MI testing by facilitating SMBus communication between the test machine and the NVMe SSD. It enables sending and receiving NVMe-MI messages, as well as interacting with other protocols such as SPDM. This allows developers to construct and transmit custom packets, monitor responses, and inject errors at different layers, including the physical, transport, and protocol layers. Additionally, the adapter supports configurable controller settings, allowing adjustments to frequency and transfer unit sizes to match specific testing scenarios.
One of the key advantages of using Aardvark is its seamless integration with PMU2. Together, these components provide complete NVMe-MI test coverage, enabling a wide range of management interface validations. PyNVMe3 also allows simultaneous testing of both out-of-band (OOB) and in-band NVMe commands, making it possible to evaluate MI interactions while performing standard NVMe operations.
By using the Aardvark I2C/SPI Host Adapter, PyNVMe3 delivers a reliable and flexible infrastructure for NVMe-MI testing, eliminating the need for dedicated server systems while providing all the essential capabilities required for thorough management interface validation.
14.4 Management Test Suite
The scripts/management directory contains specialized test scripts for validating management functionalities, including basic management commands, MI, and SPDM.
| Test Script | Description |
|---|---|
01_mi_inband_test.py |
Tests in-band management interface commands for NVMe devices. |
02_basic_mgmt_cmd_test.py |
Validates basic NVMe management commands for legacy compatibility. |
03_mi_cmd_set_test.py |
Provides comprehensive testing of the NVMe Management Interface Command Set. |
04_mi_admin_cmd_test.py |
Focuses on administrative commands within the Management Interface. |
05_mi_control_primitive_test.py |
Evaluates control primitives in NVMe devices via the Management Interface. |
06_mi_pcie_cmd_test.py |
Targets PCIe-specific commands in the NVMe Management context. |
07_mi_feature_test.py |
Tests features including endpoint buffer configurations and MCTP Transport Unit sizes. |
08_mi_error_inject_test.py |
Injects errors into MCTP and MI packet headers to assess error handling. |
09_mi_stress_test.py |
Stresses the device by interweaving MI with various commands for robust testing. |
10_mi_ocp_test.py |
Validates OCP (Open Compute Project) NVMe-MI compliance. |
11_spdm_test.py |
Tests SPDM (Security Protocol and Data Model) functionality over MCTP. |
We can start the management tests on Desktop Test Platform using the following command:
make test TESTS=./scripts/management
14.5 Fixtures and API
PyNVMe3 provides the i2c, mi, and spdm fixtures, allowing users to send various types of request messages. These include basic management commands, NVMe-MI commands, NVMe admin commands, PCIe commands, control primitives, and SPDM commands. Below are examples demonstrating how to write management-related test scripts using PyNVMe3. For more details, please check the source code under PyNVMe3/scripts/management.
Example 1: Reading Drive Static Data
def test_mi_spec_appendix_a_read_drive_static_data(i2c, buf):
""" Read drive static data (VID and serial number) via I2C. """
i2c.i2c_master_write(i2c.ENDPOINT, [8], flags=pyaardvark.I2C_NO_STOP)
buf[:] = i2c.i2c_master_read(i2c.ENDPOINT, 24)[:]
logging.info(buf.dump(64))
Example 2: Retrieving SMART Log Page
def test_mi_admin_get_log_page(mi, nvme0):
""" Retrieve SMART log page via NVMe-MI admin command. """
resp = mi.nvme_getlogpage(2, length=20).receive()
resp_data = resp.response_data(12)
ktemp = resp_data.data(2, 1)
logging.info("Temperature (via MI): %d degrees F" % ktemp)
Example 3: SPDM Get Capabilities Command
def test_spdm_get_capabilities_multiple(spdm):
""" Test SPDM GET_CAPABILITIES request with an invalid sequence. """
spdm.get_version().receive()
spdm.get_capabilities().receive()
with pytest.warns(UserWarning, match="SPDM ERROR response, code: 0x04"):
spdm.get_capabilities().receive()
15. Summary
PyNVMe3 provides a comprehensive and flexible NVMe SSD testing framework, enabling developers to perform in-depth testing on a wide range of NVMe functionalities. From basic read/write operations to advanced power management, error injection, and out-of-band commands, PyNVMe3 facilitates efficient and automated testing within the Python software ecosystem.
For more examples, please refer to the Python source code included with PyNVMe3. If you need additional assistance, feel free to contact us through the following channels:
- Email Support: support@pynv.me
- Sales and Licensing Inquiries: sales@pynv.me
- Official Website: https://pynv.me