
PyNVMe3脚本开发指南
无论在PC电脑还是数据中心的服务器上,存储都是和计算、网络同等重要的一个核心部件。计算通常指CPU,网络通常指网卡,而存储当下最热门的就是NVMe SSD了。国内外越来越多的厂商在进入这个市场,但是不同厂商的产品,甚至同一个厂商的不同产品,他们的质量都是良莠不齐的。
SSD需要有完整的功能,优异的性能,以及高度的数据可靠性。个人使用的消费级SSD还需要有良好的兼容性,以及低功耗表现。不论是刚起步3-5年的初创公司,还是已经在这个行业里面有10年多的老公司,要能做一款优秀的达到上述各种要求的SSD盘并不容易。特别从存储的数据可靠性来看,SSD的质量尤其重要。毕竟,网络断了可以重连,包丢了可以重发;CPU坏了可以换,AMD不行换Intel,Intel不行换AMD。但是SSD市场上那么多厂商那么多产品,如果用了不好的SSD盘导致数据丢失,那换什么都来不及了。
目前很多厂商在测试NVMe SSD的时候大量依赖传统的测试工具,譬如fio/nvme-cli/dnvme和其他一些商业工具。这些工具可以做一些功能性测试,但它们的性能无法满足越来越快的NVMe/PCIe的规格。性能跟不上,测试压力就不够,有些缺陷就压不出来。另外,这些工具对测试脚本的二次开发并不友好,无法满足不同场景下成百上千的测试用例开发的需要。我们有近十年的SSD固件开发经验,在经历过种种来自测试工具的痛苦和教训之后,我们决定自己做一个灵活的NVMe SSD测试工具。我们的目的是帮助厂商测好SSD,帮助客户选好SSD。
这就是PyNVMe3。经历了5年多的研发和推广,PyNVMe3作为一个第三方独立的测试工具,已经被国内外许多SSD厂商和客户采用。各个厂商对使用PyNVMe3自行开发测试脚本的兴趣也与日俱增,所以我们整理了这份PyNVMe3脚本开发指南,让大家能更快开始PyNVMe3的测试脚本开发。
测试平台
PyNVMe3是一个纯软件的测试工具,可以工作在各种电脑或者服务器上面,用户不需要花大价钱购买专用的测试硬件平台,方便厂商低成本大规模地部署测试。在安装PyNVMe3之前,请检查平台是否满足以下要求:
- CPU: x86_64平台。AMD平台需要添加内核启动参数,请参考下文的安装和配置部分。
- OS: Ubuntu 20.04.x,推荐将OS安装到SATA盘上。目前只支持Ubuntu 20.04版本。
- 需要sudo/root权限。
- RAID mode (Intel® RST)需要在BIOS中关闭。
- Secure boot需要在BIOS中关闭。
服务器需要额外检查以下BIOS配置:
- IOMMU: (a.k.a. VT for Direct I/O)需要在BIOS中关闭。
- VMD: 需要在BIOS中关闭。
- NUMA: 需要在BIOS中关闭。
准备工作
首先要安装Ubuntu 20.04,建议使用SATA SSD作为OS系统盘。
普通用户使用sudo获取root权限时经常需要输入密码,稍显麻烦。我们建议先做如下免密配置:
- 在Ubuntu 20.04命令行环境下执行下面的命令,系统会自动打开默认的编辑器nano。
> sudo visudo
- 在最后一行输入:
your_username ALL=(ALL) NOPASSWD: ALL
- Ctrl-o,回车,写入配置文件。然后Ctrl-x退出编辑器。后面再用到sudo就不需要输入密码了。
安装和配置
PyNVMe3需要在终端中通过命令行来安装,大部分环节我们做了自动化处理,所以安装并不复杂。具体过程如下:
- PyNVMe3会用到很多python库,需要先安装pip3。
> sudo apt install -y python3-pip
- 国内用户需要更改pip3的下载源。创建或修改~/.pip/pip.conf配置文件,添加一下内容并保存。
[global] index-url=https://pypi.tuna.tsinghua.edu.cn/simple/ [install] trusted-host=pypi.tuna.tsinghua.edu.cn
- 如果之前安装过PyNVMe3,请先卸载PyNVMe3。
> sudo pip3 uninstall PyNVMe3 > sudo rm -rf /usr/local/PyNVMe3
- 用pip3安装PyNVMe3,PyNVMe3会安装在/usr/local/PyNVMe3目录下。如果没有安装文件,请联系sales@pynv.me。
> sudo pip3 install PyNVMe3-22.11.tar.gz
- 用root权限打开/etc/default/grub文件,并修改GRUB_CMDLINE_LINUX_DEFAULT这一行如下:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash default_hugepagesz=2M hugepagesz=1G hugepages=1 amd_iommu=off"
- 在命令行中执行:
> sudo update-grub
- 在 /etc/fstab文件最后一行添加:
none /mnt/huge hugetlbfs pagesize=1G,size=1G 0 0
- 至此我们完成了PyNVMe3的安装和配置工作,重启一下测试机器就可以开始使用PyNVMe3了。
> sudo reboot
执行测试
PyNVMe3有几种不同的执行方式:
- 在VSCode下执行,主要用来调试新的脚本。
- 在命令行环境下执行。
- 在Jenkins等CI环境下执行。
我们这里通过命令行环境来介绍PyNVMe3的测试执行。
- 进入PyNVMe3目录:
> cd /usr/local/PyNVMe3/
- 切换到root用户:
> sudo su
- 配置运行时环境。这一步会把NVMe设备的内核驱动更换成PyNVMe3的用户态驱动,并预留大页内存给测试使用。
> make setup
当我们测试消耗的大页内存比较多时,需要预留更多大页内存。用户可以用memsize参数来预留更多大页内存:
> make setup memsize=10000
默认情况下,PyNVMe3会尝试预留10G大页内存,这个能满足4TB容量盘(LBA大小为512字节)的测试需要。建议测试机配置16G或以上的内存。关于大页内存可以参考后文Buffer部分。
- 执行测试使用如下命令:
> make test
这条命令默认执行scripts/conformance目录下的所有测试项目。conformance目录下包含了完整的NVMe协议规范测试,整体测试时间大概需要2-3小时。在scripts/benchmark目录下有其他更多测试,这些benchmark测试需要指定具体的文件名字,并且需要完整执行整个文件的测试,而不是其中的某个函数。通常执行的时间比较长,几个小时、几天、几周不等。譬如执行我们的性能测试脚本:
> make test TESTS=scripts/benchmark/performance.py
如果测试平台上面有多个NVMe待测设备,需要通过pciaddr参数指定被测设备的BDF地址。
> make test pciaddr=0000:03:00.0
如果平台上只有唯一的NVMe盘,就不需要指定这个参数,PyNVMe3会自动找到这个盘的BDF地址。这也是我们推荐使用SATA盘安装OS系统的原因。
对于多Namespace的NVMe盘,可以通过nsid参数来指定测试的Namespace,默认情况是1。
> make test nsid=2
make test命令行可以组合使用TESTS/pciaddr/nsid这些参数。
- 收集测试结果。测试开始后会在终端实时打印测试日志,也可以在results目录下找到测试日志文件。测试日志文件会比终端打印的测试日志包含更多调试信息。每一个测试项目可能有如下结果:
- SKIPPED: 测试被跳过,由于某些条件不成立,测试不需要执行。
- FAILED: 测试失败。日志文件里面可以看到测试失败的具体原因,通常是某个assert断言不满足。当一个assert失败以后,这个测试项目会立刻退出,不会继续执行后续的测试步骤。
- PASSED: 测试通过。
- ERROR:测试无法执行。可能被测NVMe盘已经丢失。如果遇到ERROR,建议检查上一个FAILED测试项目的日志,可能是这里的FAILED导致丢盘以及后续的ERROR。
不论测试结果如何,都有可能在测试过程中产生warning。测试日志中包含了所有warning的列表。大部分warning可能和AER返回或者NVMe命令的error code相关,是正常现象。但我们还是建议仔细检查所有warning信息。
results目录下不仅包含测试的日志文件,还有一个excel格式的测试报告,以及测试脚本生成的其他文件(譬如测试记录的原始数据和图表等)。
- make test在测试正常结束后会自动切换回NVMe设备的内核驱动。用户也可以在命令行中手动切换内核驱动,以执行其他基于内核驱动的工具(譬如fio/nvme-cli等)。
> make reset
作为和make setup相反的操作,make reset切换回NVMe设备的内核驱动。但需要注意的是,make reset并不会释放make setup申请到的大页内存。因为这些内存一旦释放,由于内存碎片化,后续的make setup很可能无法再次申请到同样大小的大页内存。因此,我们也建议用户在OS启动后的第一时间就执行make setup,确保可以预留所需的大页内存。
pytest
PyNVMe3是一个完整的NVMe SSD测试平台,但我们的主要工作集中在设备驱动部分,并将这个驱动封装成Python库,提供Python API给用户脚本使用。这样,我们的工具可以完全融入Python的生态,整合Python生态中的各种第三方工具。pytest正是其中一个非常重要的第三方工具。
pytest是一个通用的测试框架,可以帮助测试开发人员编写从简单到复杂的各种测试脚本。下面我们介绍pytest的一些基本用法和特性,更多详情请参考pytest官方文档。
编写测试
pytest会自动收集测试脚本中以test_开头的函数,作为测试函数。然后pytest会逐个调用这些测试函数。下面是一个完整的测试文件。
import pytest def test_format(nvme0n1): nvme0n1.format()
是的,只有3行,这就是一个完整的pytest测试文件。pytest的测试脚本是非常简洁的。
测试文件只需要导入pytest模块,然后就可以直接写测试函数。
当我们不想执行某个测试函数时,建议在函数名开头加下划线_,pytest就不会收集这个测试函数,譬如:
import pytest def _test_format(nvme0n1): nvme0n1.format()
命令行
pytest支持多种从命令行执行测试的方法。如前文所述,PyNVMe3使用make test命令行执行测试,但也可以直接使用pytest命令行来执行测试。例如以下几种命令行,分别用来执行一个目录下面的所有测试,一个文件里面的所有测试,以及一个指定的测试函数。
> sudo python3 -B -m pytest scripts/conformance > sudo python3 -B -m pytest scripts/conformance/01_admin/abort_test.py > sudo python3 -B -m pytest scripts/conformance/01_admin/abort_test.py::test_dut_firmware_and_model_name
assert断言
pytest允许使用Python的断言语句assert来检查测试中的数据,例如:
def inc(x): return x + 2 def test_inc(): assert inc(1) == 2, "inc wrong: %d" % inc(1)
由于inc函数的错误实现,上面的assert断言会失败。pytest会报告测试FAIL,并打印失败的具体信息,包括assert语句逗号后面的字符串。我们可以根据日志里面的这些信息来调试脚本和固件。好的断言可以提供FAIL现场的足够信息,以提高开发和调试的效率。
fixture
pytest有一个非常重要的特性叫做fixture。fixture可以说是pytest的精髓,我们非常粗浅地通过一些例子来介绍fixture的基本用法,更详细的内容可以参考官方文档。
下面脚本包含两个fixture:nvme0和nvme0n1,以及一个测试函数使用了这两个fixture。
@pytest.fixture() def nvme0(pcie): return Controller(pcie) @pytest.fixture(scope="function") def nvme0n1(nvme0): ret = Namespace(nvme0, 1) yield ret ret.close() def test_dut_firmware_and_model_name(nvme0: Controller, nvme0n1: Namespace): # print Model Number logging.info(nvme0.id_data(63, 24, str)) # format namespace nvme0n1.format()
fixture是一个特别的函数,用来初始化测试所需的对象。定义fixture只需要在函数上加装饰器@pytest.fixture(),fixture命名不要用test_开头,跟测试函数区分开。要使用一个fixture时,直接在测试函数的参数列表里面添加这个fixture的名字就可以了。在执行测试的时候,pytest会调用对应fixture的实现函数,并将返回对象传递给这个fixture的名字。这样测试函数就可以直接使用这个测试对象了。
fixture可以将测试对象的创建和释放过程封装起来给测试函数使用。PyNVMe3中定义了很多这样的NVMe盘的测试对象,譬如:pcie, nvme0, nvme0n1, cq, sq等等。有了fixture,我们就不需要在每个测试函数中去反复写代码创建或释放测试对象了。测试函数的参数列表里面可以添加任意多个fixture,而且无需特别注意他们的先后关系。
fixture初始化的测试对象可以通过return语句返回,也可以用yield返回。yield之后的代码会在测试完成后由pytest再次调用,一般用来释放这个测试对象。
fixture可以相互依赖,譬如上面脚本中的nvme0n1依赖于nvme0。测试脚本只需要在fixture的参数列表里面引用其他被依赖的fixture,pytest会自动调整fixture调用的先后顺序。fixture可以按照正确的顺序帮脚本初始化并释放所有测试对象,当测试涉及到很多对象的时候这个特性尤其重要。
fixture包含一个叫做scope的可选参数,用于控制fixture被调用的时机。譬如上面的nvme0,其scope是function,所以在每个测试函数被执行之前pytest会调用nvme0,这样每个测试函数都会重新初始化NVMe盘,可以隔离不同测试的错误。
fixture的名字可以被重载,在同一个测试文件内定义的fixture具有最高优先级。fixture也可以放在conftest.py文件中。conftest.py是pytest定义的专门用来集中存放fixture的文件。不同的目录可以有不同的conftest.py文件,pytest在执行测试的时候,会按照就近原则从测试文件或者某个conftest.py里面找到fixture的定义。
PyNVMe3提供了联机帮助文档,但是IDE并不知道fixture的类型,所以需要使用Python3的新特性:type hint。如下面这个脚本,通过type hint告诉IDE nvme0是一个Controller对象,这样IDE会自动跳出nvme0及其方法的帮助文档。
def test_dut_firmware_and_model_name(nvme0: Controller, nvme0n1: Namespace): # print Model Number logging.info(nvme0.id_data(63, 24, str)) # format namespace nvme0n1.format()
总而言之,pytest的fixture是一种简洁又极具扩展能力的测试工具,PyNVMe3定义并使用了大量fixture。
参数化
测试用例经常会做参数化的设计,譬如在不同的LBA起始地址写入不同LBA长度的数据。pytest也提供了一种便捷的实现方式。譬如下面这个测试脚本,pytest会用所有不同的(lba_start, lba_count)组合来执行这个测试用例,共计4×4=16个测试。
@pytest.mark.parametrize("lba_start", [0, 1, 8, 32]) @pytest.mark.parametrize("lba_count", [1, 8, 9, 32]) def test_write_lba(nvme0, nvme0n1, qpair, lba_start, lba_count): buf = Buffer(512*lba_count) nvme0n1.write(qpair, buf, lba_start, lba_count).waitdone()
pytest大概介绍到这里,这并不是pytest的全部,还有更多便利的设计等待我们去发掘和利用。
Visual Studio Code (VSCode)
工欲善其事,必先利其器。要写好脚本,就要先找一个趁手的IDE。我们推荐VSCode。VSCode是微软官方的一个开源项目,是一个轻量级但有丰富扩展的代码编辑器,可以在Windows,MacOS和Linux等系统上使用。并且,微软官方也提供了支持Python的插件,长期持续改进对Python以及pytest的支持。PyNVMe3也提供了一个VSCode下的插件,用于显示队列、命令日志以及实时性能等测试信息。VSCode主要用于开发和调试测试脚本,正式的执行测试我们依然建议使用命令行环境或者CI环境。
在通常的测试环境中,我们会有不同的测试机放在实验室中,但我们并不希望长期在实验室中调试代码。VSCode支持远程的工作方式,只需要在自己的工作机上安装VSCode,通过ssh远程链接到测试机来调试测试脚本,使用体验和本地调试一模一样。
我们以远程的工作方式来介绍VSCode的配置和使用步骤。
- 从官网下载VScode软件安装包,在工作机上安装VSCode。工作机可以是Windows/MacOS/Linux等系统。
- 安装Remote-SSH插件。
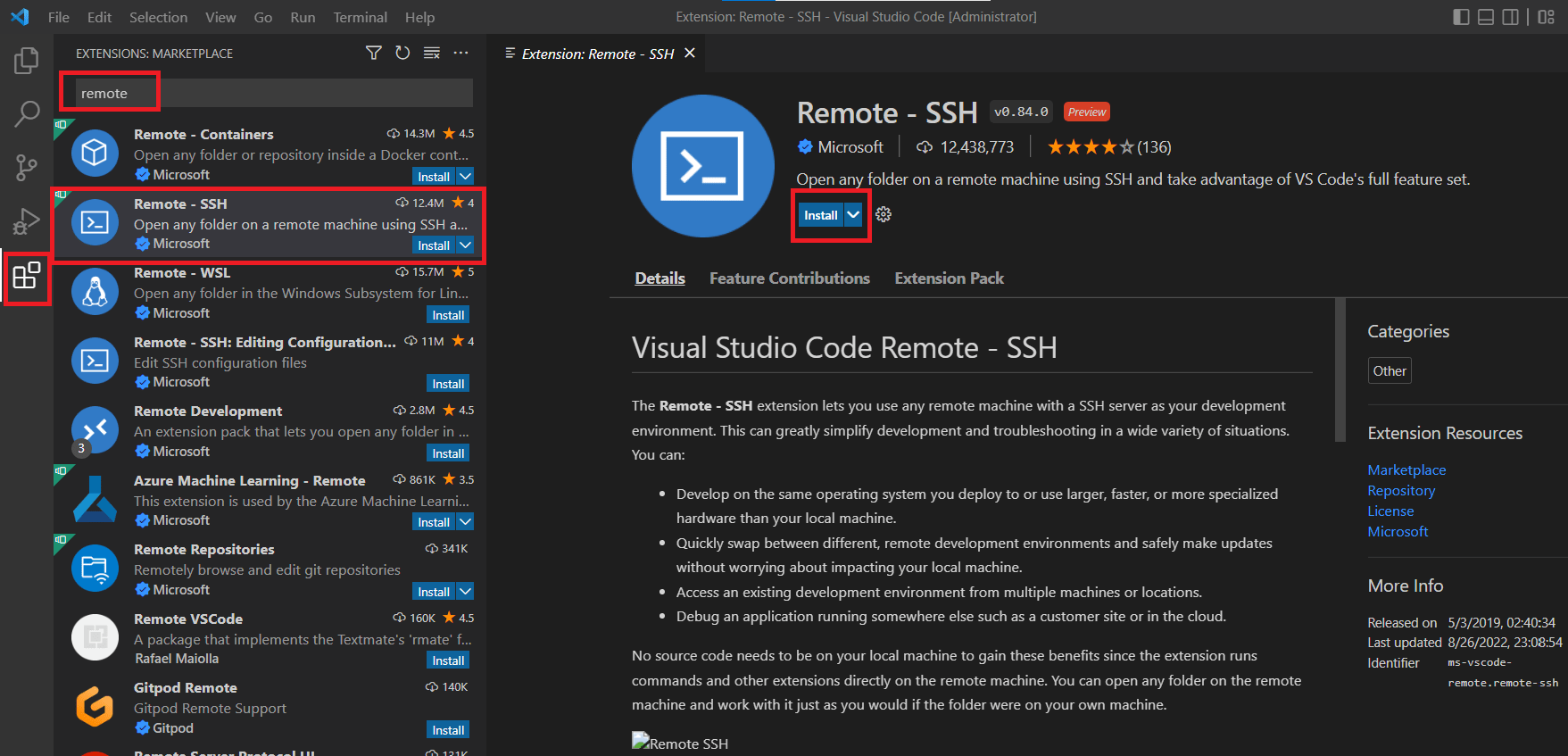
如果要使用测试机的root账号远程登录,需要更改测试机的ssh配置。首先打开配置文件:> sudo vim /etc/ssh/sshd_config
找到并用#注释掉这行:PermitRootLogin prohibit-password。然后新建一行添加:
PermitRootLogin yes
最后重启SSH:
> sudo service ssh restart #重启ssh服务 > sudo passwd root #如果root没有密码,需要设置密码
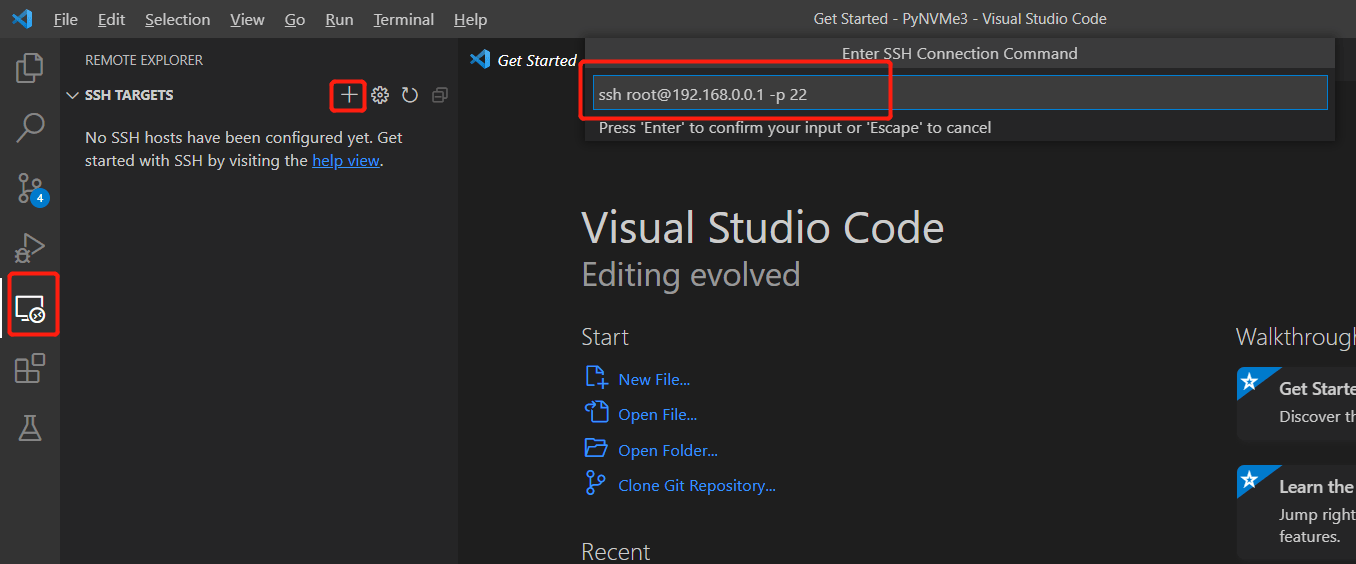
- 配置Remote-SSH连接到测试机器。从左到右依次点击下图红框中图标,并输入ssh命令行,可以用参数-p指定自定义的ssh端口。然后按回车。
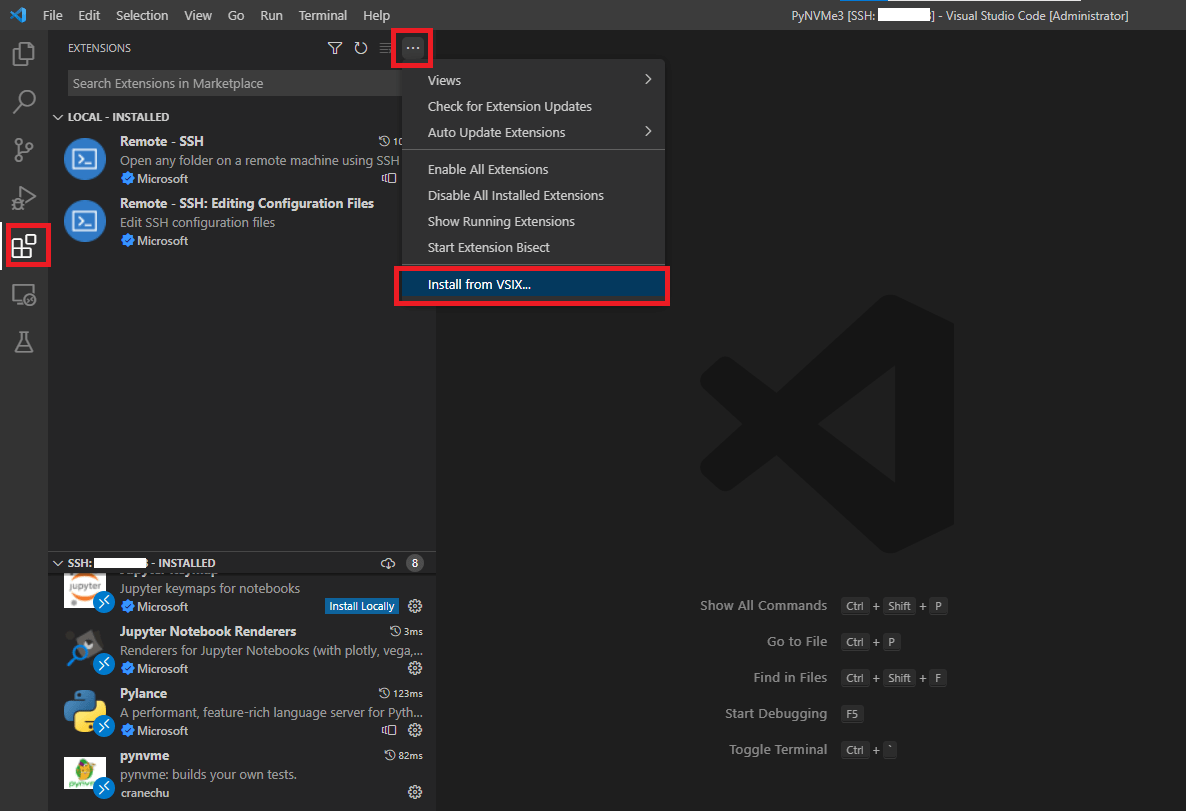
- 在VSCode远程窗口中安装PyNVMe3插件。点击install from VSIX,查找到PyNVMe3/.vscode目录下的插件,并安装。
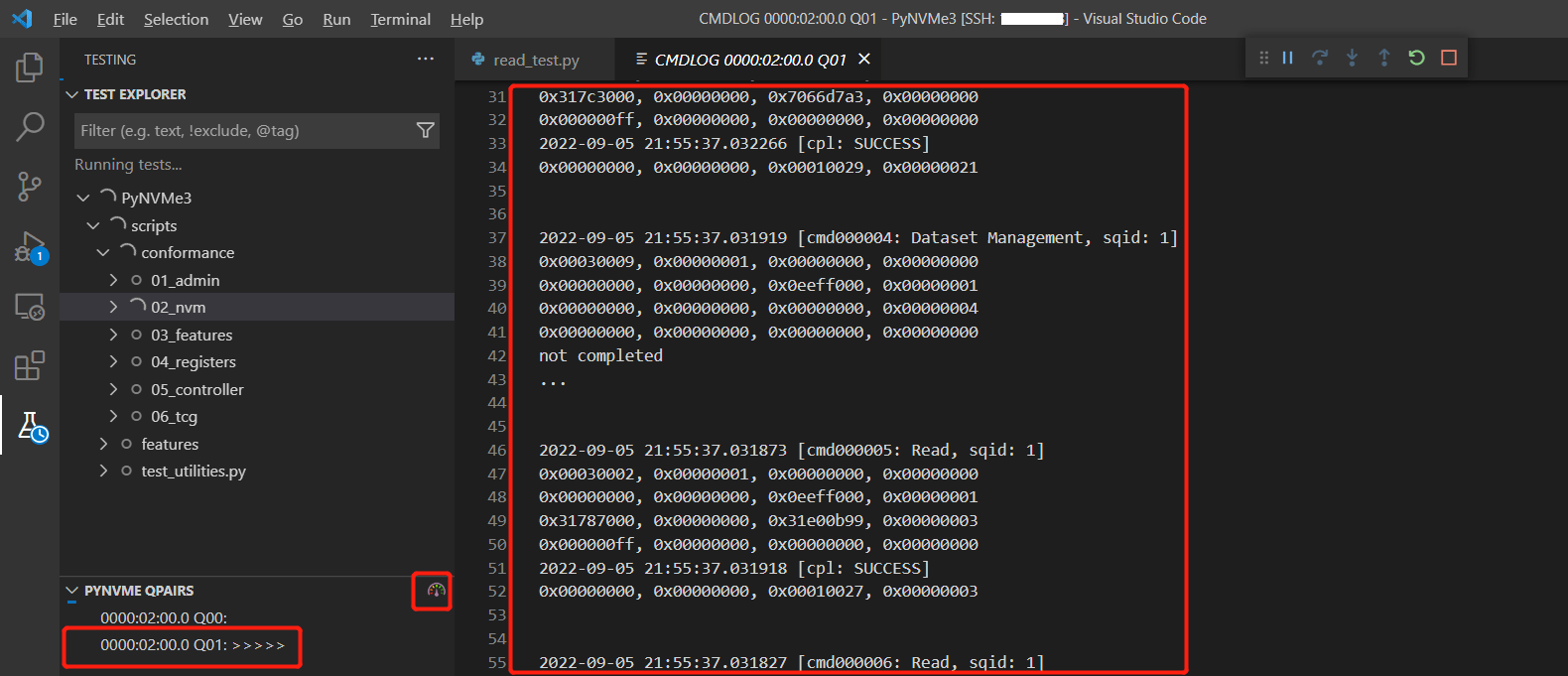
- 如下图所示,PyNVMe3的VSCode插件可以显示当前的队列和命令日志。点击速度码表的图标还可以显示当前性能。
- 在VSCode远程窗口中打开PyNVMe3文件夹。
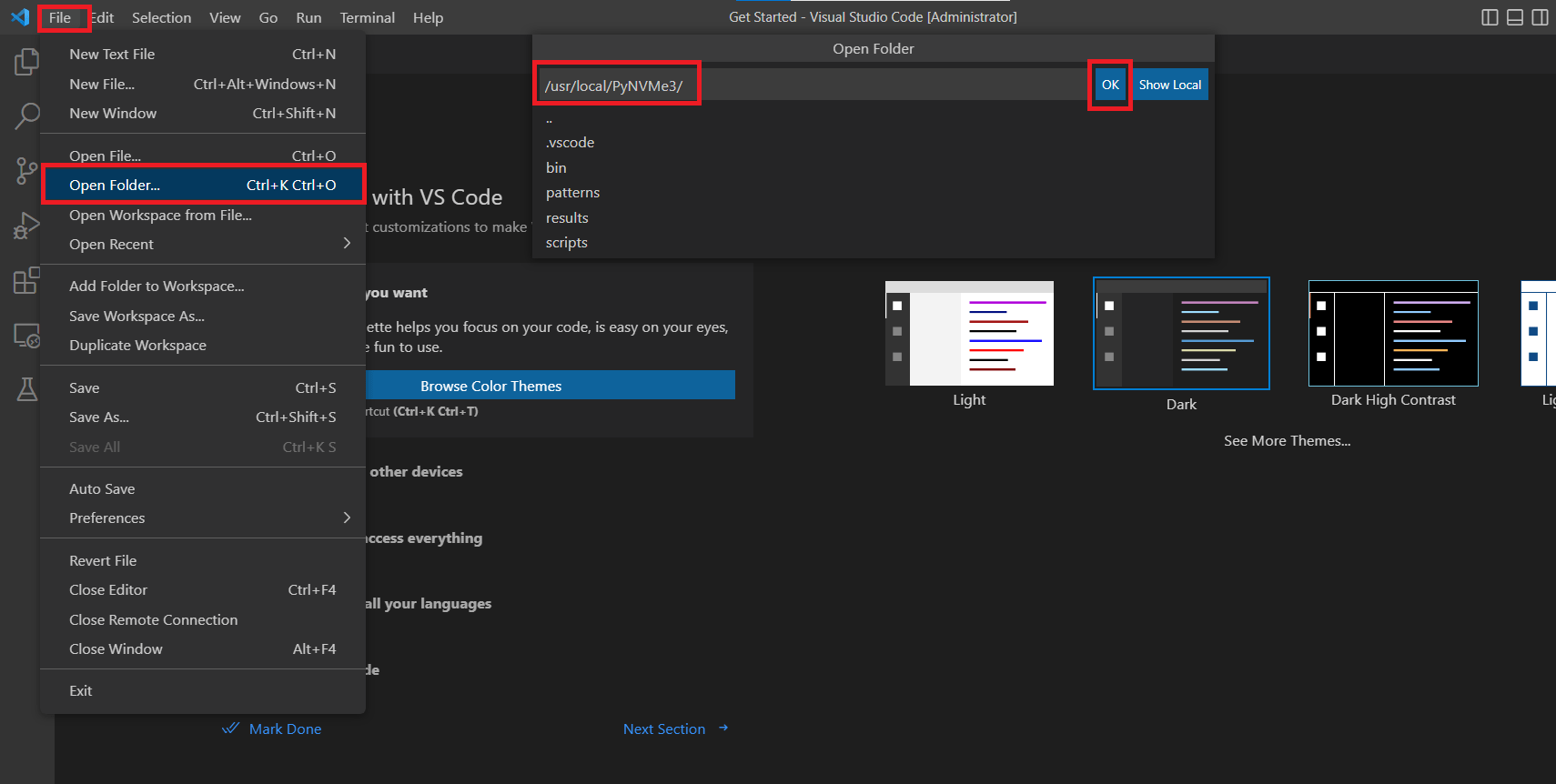
- 打开终端并执行make setup命令。
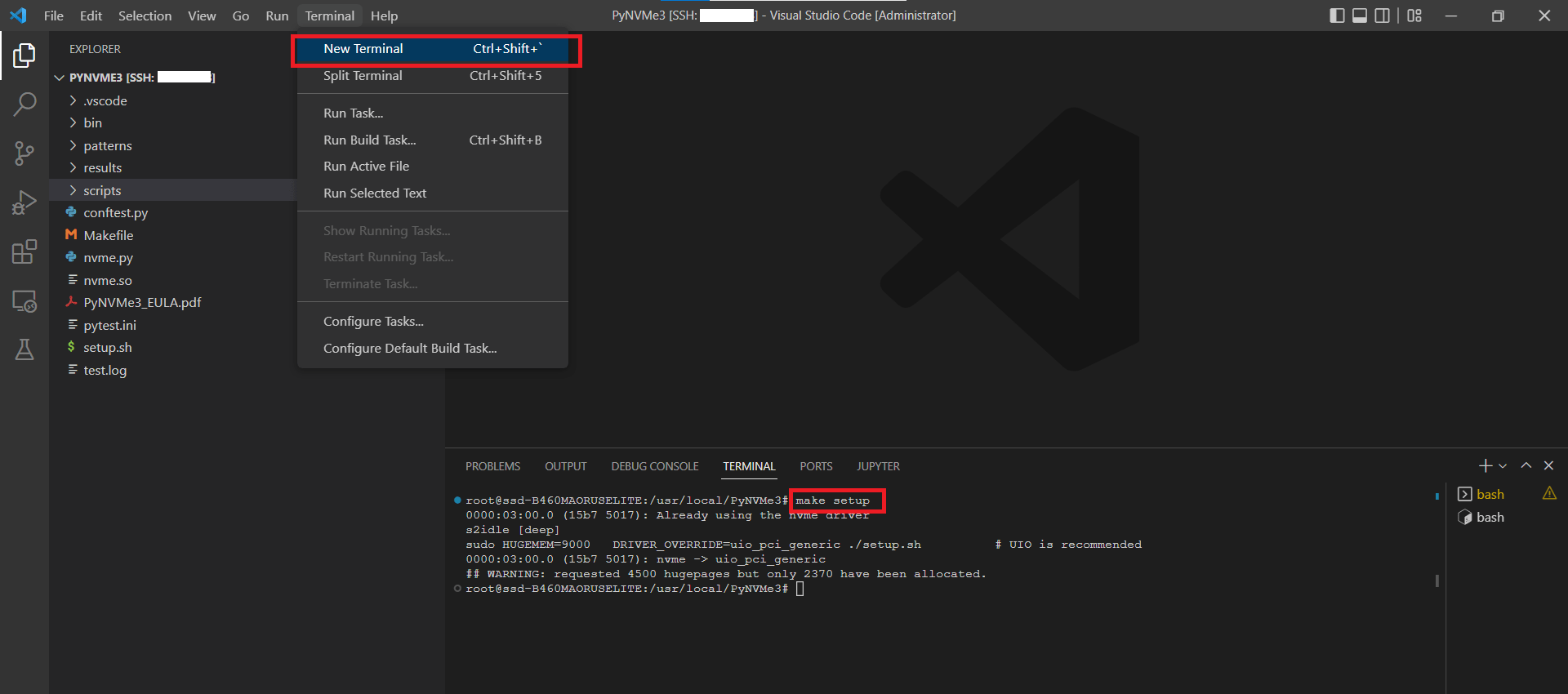
- 配置NVMe设备的BDF地址。可以参考make setup命令打印出的NVMe设备信息。
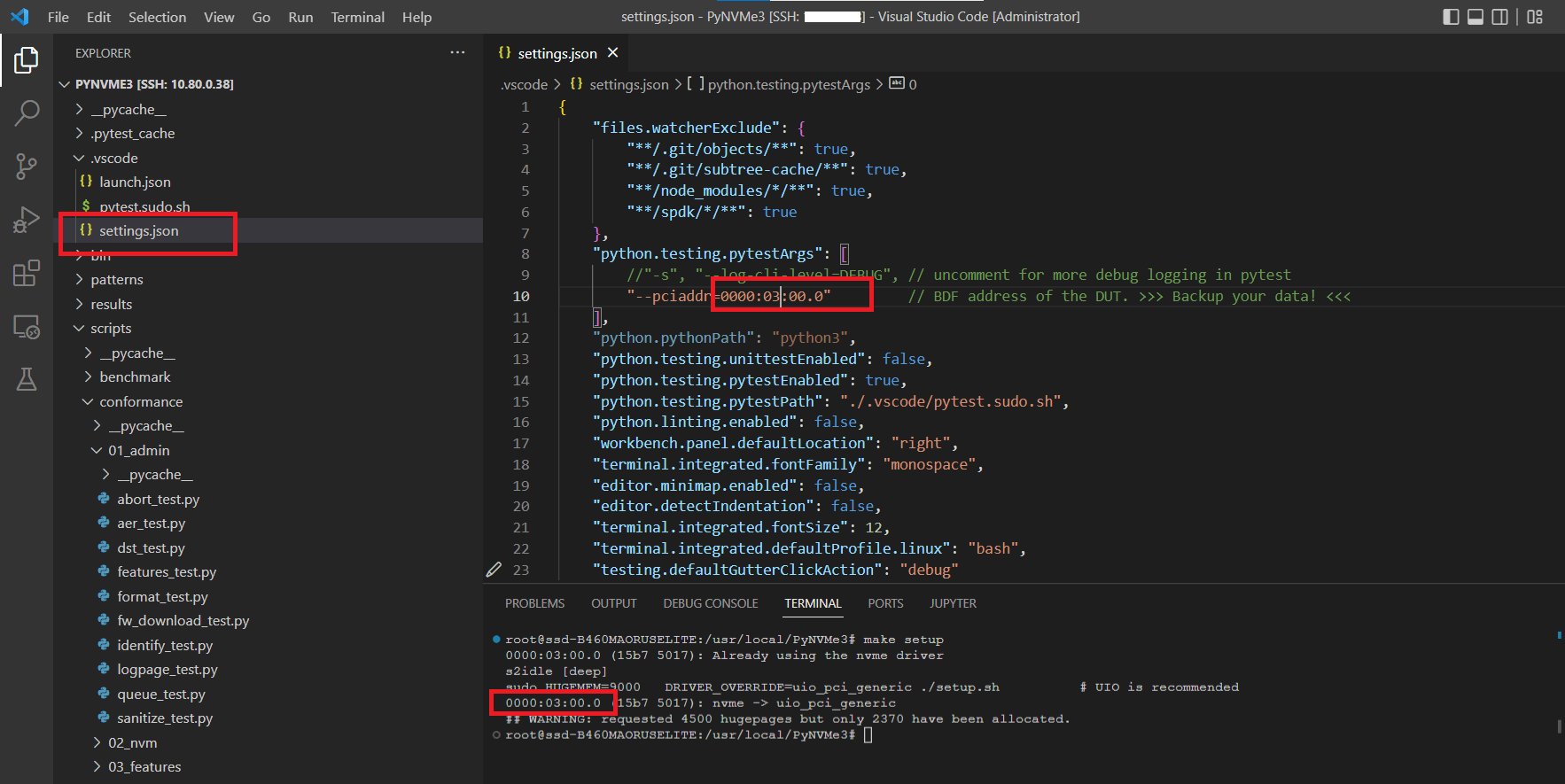
- pytest收集测试用例。点击左侧小药瓶图标即可展开测试相关的面板,这里会显示pytest收集到的所有测试用例。目前VSCode需要测试文件名也包含test,pytest命令行没有这个限制。点击脚本文件行号左侧的三角按钮即可运行测试。对于参数化的测试用例,需要右击三角按钮选择其中一项进行测试。
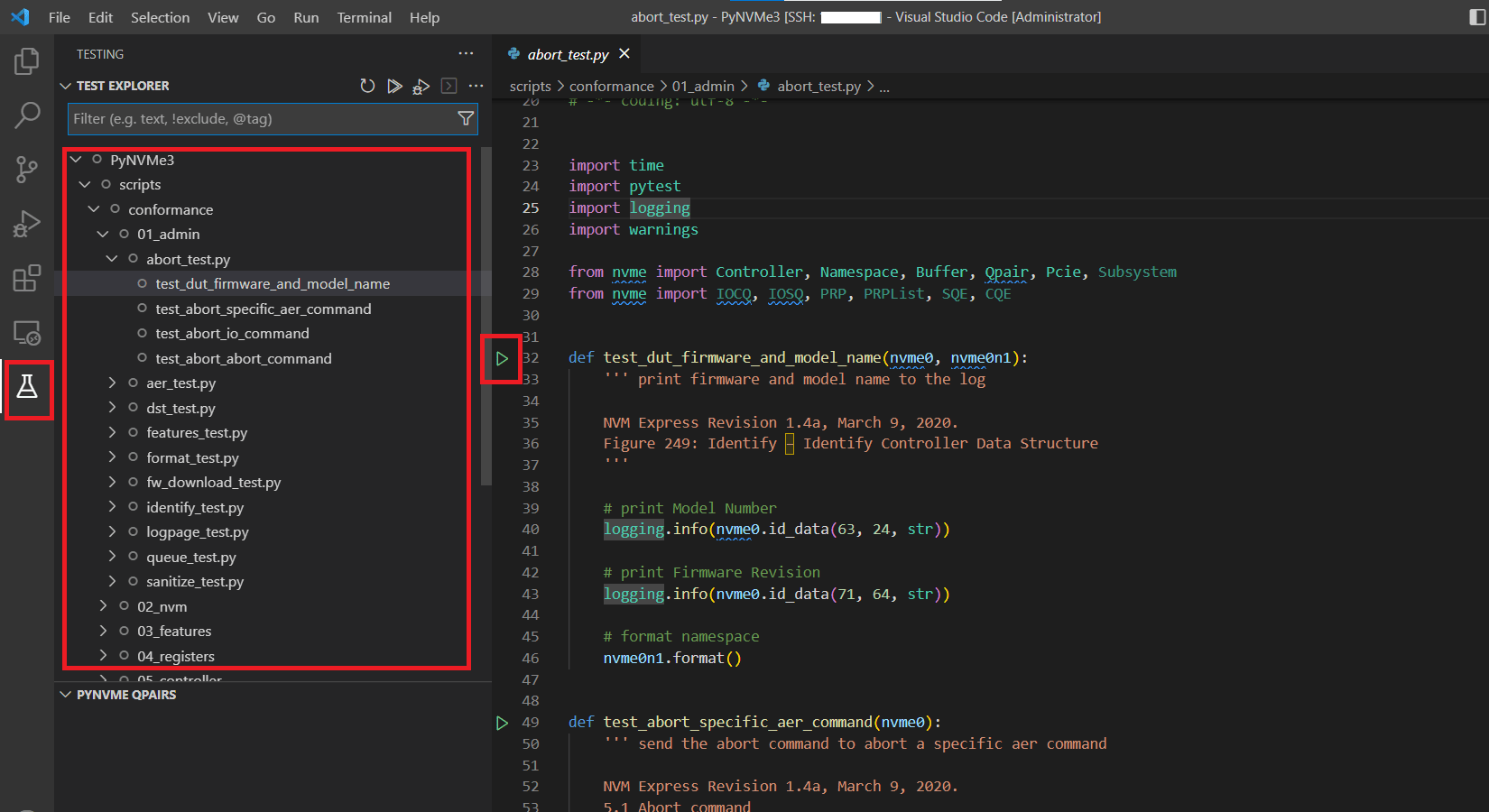
- VSCode执行测试时,在终端界面中也可以看到测试日志,但不会在results目录下保存日志文件。
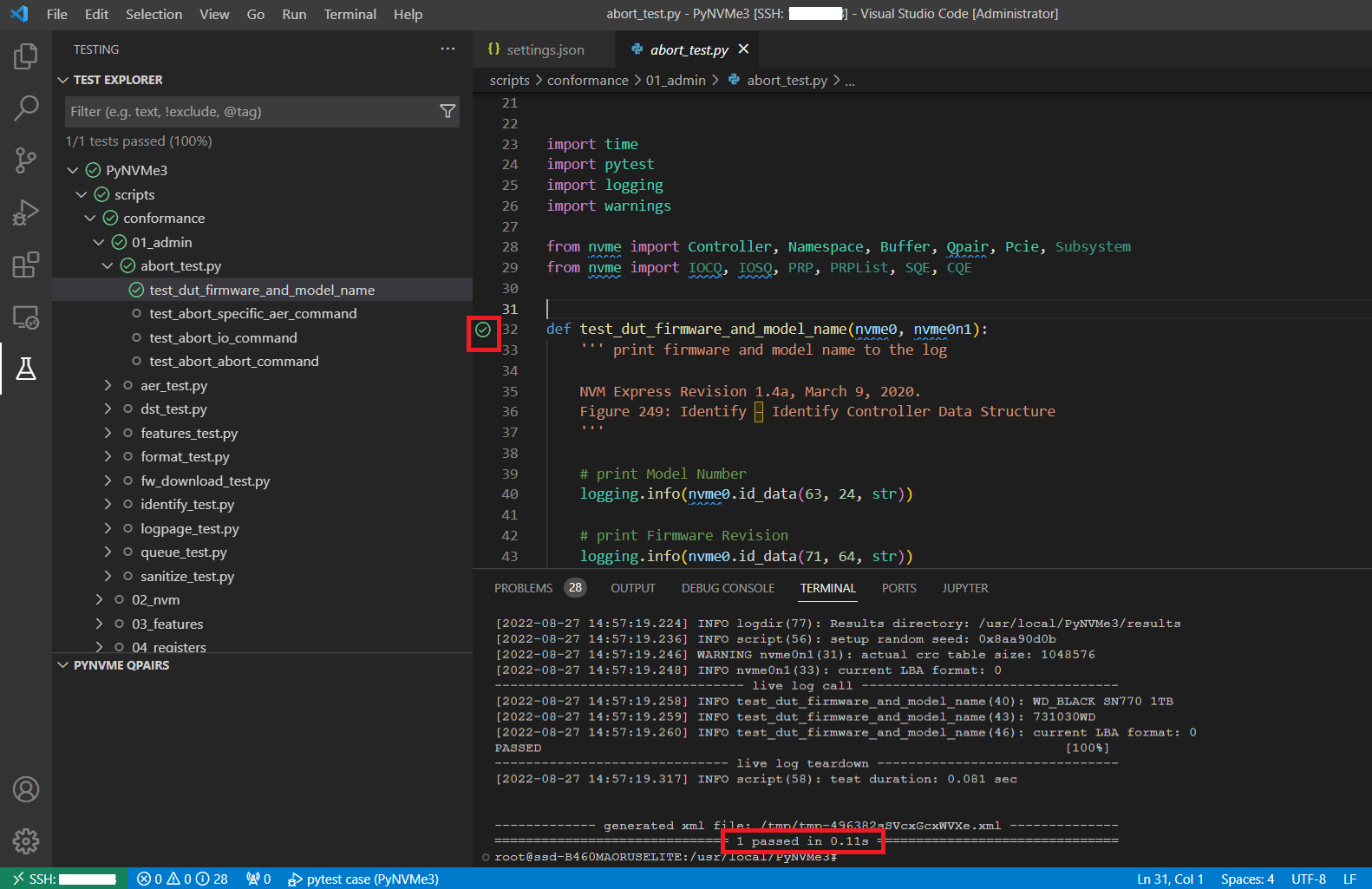
- VSCode执行测试,默认使用Debug方式。可以在VSCode中添加断点,利用VSCode提供的调试面板来调试脚本。断点触发后,PyNVMe3的扩展依然在工作,可以查看这个工作场景下的队列和命令日志,调试脚本更加得心应手。这里需要注意PyNVMe3驱动有timeout时间的限制,如果断点触发的时候有outstanding命令,后续执行过程可能会看到timeout被触发。
请避免在有outstanding命令的地方设置断点。
基础脚本
PyNVMe3的软硬件平台准备就绪后,我们就可以开始写NVMe SSD的测试脚本了。
每一个测试脚本文件都需要先导入一些模块,包括pytest,logging,当然还有PyNVMe3的驱动模块(nvme.so)。下面是一个典型的完整的测试脚本文件。
import pytest import logging from nvme import * def test_dut_firmware_and_model_name(nvme0: Controller): logging.info("model name: %s" % nvme0.id_data(63, 24, str)) logging.info("current firmware version: %s" % nvme0.id_data(71, 64, str)) logging.info("PyNVMe3 conformance test: " + __version__)
我们直接导入PyNVMe3驱动模块提供的所有类和变量,常用的类包括:Controller, Namespace, Qpair等。__version__可以获取导入的PyNVMe3驱动模块的版本。
PyNVMe3可以对NVMe测试盘做各种操作和测试,但我们先通过读写操作来快速浏览几个PyNVMe3的基础脚本。PyNVMe3支持3种不同的方式来发送IO,以适应不同的测试需求。
ns.cmd
ns.cmd是一种简单直接的发送IO的方式,通过这种方式我们可以发送read、wirte、trim、wirte uncorrectable等等命令。PyNVMe3提供了几乎所有IO命令的接口。
ns.cmd通过io qpair发送命令,所以我们需要在测试函数的参数列表中引用qpair。这个fixture会在测试开始的时候创建一个io qpair,并在测试结束的时候删除这个io qpair。
io操作发生在namespace上面。PyNVMe3定义了默认的nsid为1的namespace fixture,按照内核驱动的命名习惯称为nvme0n1。这个fixture在测试开始的时候会创建namespace在驱动中的对象,并在测试结束的时候释放。nvme0n1这个fixture依赖于nvme0,一个创建Controller对象的fixture。虽然测试函数没有引用这个fixture,但pytest会自动根据依赖关系,调用这个fixture。
下面是一个发送读写命令的测试函数的示例,可以看到fixture使其实现非常简洁。
def test_write_read(nvme0n1, qpair): read_buf = Buffer(4096) write_buf = Buffer(4096) nvme0n1.write(qpair, write_buf, 0).waitdone() nvme0n1.read(qpair, read_buf, 0).waitdone()
脚本通过ns.cmd发出命令以后不会等待命令返回,而是直接继续往下执行。如果我们需要等待命令完成,可以调用waitdone()。PyNVMe3会在waitdone()中回收指定个数的CQE,默认为1。
NVMe是一种完全异步的IO协议,系统驱动经常使用回调机制来处理这种IO完成之后的操作。PyNVMe3也提供了回调的工作方式,可以让测试脚本定义每一条IO命令结束以后的处理代码。回调函数由PyNVMe3的驱动在waitdone里面调用。
下面的测试函数和上面的例子具有一样的行为,但读命令是在write命令的回调中发出。由于回调函数是在waitdone里面调用,所以PyNVMe3规定在回调函数里面不可以再调用waitdone。
def test_io_callback(nvme0, nvme0n1, qpair): read_buf = Buffer(4096) write_buf = Buffer(4096) def write_cb(cpl): nvme0n1.read(qpair, read_buf, 0) nvme0n1.write(qpair, write_buf, 0, cb=write_cb) qpair.waitdone(2)
我们通常在回调函数中把盘返回的CQE传递出来,供后续脚本使用。
def test_io_callback(nvme0n1, qpair): write_buf = Buffer(4096) # issue write and read command cdw0 = 0 def write_cb(cqe): # command callback function nonlocal cdw0 cdw0 = cqe[0] nvme0n1.write(qpair, write_buf, 0, 1, cb=write_cb).waitdone()
ioworker
我们可以用脚本通过ns.cmd发送大量IO,但不论开发还是执行的效率都很低。PyNVMe3提供了一个IO发生器:ioworker。ioworker在子进程中按照脚本指定的workload来自主地发送并回收IO。ioworker可以制造出高性能大压力的准确的IO操作,在主流测试平台中单核CPU可以实现120万以上的IOPS性能。脚本可以通过Namespace.ioworker()这个API来创建ioworker对象,通过ioworker对象的start方法来启动ioworker。这时ioworker运行在子进程中,并且脚本的主进程可以执行其他操作。脚本通过ioworker对象的close方法来等待ioworker子进程结束。下面是用ioworker做4K对齐随机写2秒的例子。
def test_ioworker(nvme0, nvme0n1, qpair): r = nvme0n1.ioworker(io_size=8, # 4K io size lba_align=8, # 4K aligned lba_random=True, # random read_percentage=0, # write time=2).start().close()
PyNVMe3为ioworker实现了with语句,使得脚本更加易读。譬如下面这个脚本,开启一个ioworker,当这个ioworker在运行的时候,主进程每隔一秒打印一次当前的性能数据。当然,主进程这时可以做任何事情,包括发送admin和IO命令,甚至各种reset和电源开关操作。
with nvme0n1.ioworker(io_size=8, time=10) as w: while w.running: time.sleep(1) speed, iops = nvme0.iostat() logging.info("iostat: %dB/s, %dIOPS" % (speed, iops))
ioworker为SSD测试提供了非常多的功能,可以直接在Python脚本中制造各种IO负载,并回收各种统计数据。后面我们会继续深入介绍ioworker。
metamode
ns.cmd和ioworker都工作在PyNVMe3的NVMe驱动之上,使用方便,但会受到NVMe驱动的一些限制。PyNVMe3还提供了第三种IO操作,叫做metamode。这种操作可以跳过PyNVMe3的NVMe驱动,直接把NVMe SSD作为一个PCIe设备进行测试,能对NVMe协议达到全方位无死角的测试覆盖度。metamode需要测试脚本来定义IOSQ/IOCQ/SQE/CQE/PRP/SGL等数据结构,甚至脚本也要操作Doorbell。这些要求增加了脚本实现的复杂度,但也极大地提高了测试脚本的能力和覆盖程度。
下面这段脚本利用metamode同时发出了两条具有相同cid的命令。这类错误注入对常规的软件是很难实现的。
def test_metamode_write(nvme0): cq = IOCQ(nvme0, 1, 10, PRP(10*16)) sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq) sqe = SQE(1<<16, 1) sq[0] = sqe sq[1] = sqe sq.tail = 2
以上我们通过3种不同的IO发送方式,介绍了PyNVMe3提供的测试方法。我们在驱动层面发掘各种NVMe盘测试的能力,目的是为了帮助厂商测好SSD。
下面几个章节我们将深入介绍PyNVMe3提供的类和方法,以及使用这些API的注意事项。为了简化细节,后续脚本假设测试盘的LBA是512字节。
Buffer
NVMe/PCIe是一种基于共享内存设计的协议,在测试脚本中经常需要申请一段内存用于存放用户数据、队列、PRP/SGL等数据。Buffer类可以用来申请这些内存,而且这些内存的物理地址是固定且连续的。下面我们通过一些例子来展示Buffer的用法。
- Buffer对象作为读写数据的buffer。PyNVMe3的buffer对象不会被OS换入换出,所以始终存在固定的物理地址上,可以满足DMA操作的要求。下面例子中我们创建了一个1MB的Buffer用于读命令。
def test_read(nvme0n1, qpair): read_buf = Buffer(512) nvme0n1.read(qpair, read_buf, 0, 1).waitdone()
前文我们提到通过make test预留大页内存。Buffer对象申请到的内存就是来自这些预留的大页内存。如果需要申请长度超过1MB的Buffer,需要打开1GB大页内存。当内存分配失败时,Buffer实例化会抛出异常。
- Buffer对象也可以用做DSM命令的range list,并通过Buffer.set_dsm_range()填写range list。
def test_trim(nvme0n1, qpair): buf_dsm = Buffer(4096) buf_dsm.set_dsm_range(0, 1, 1) buf_dsm.set_dsm_range(1, 2, 1) buf_dsm.set_dsm_range(2, 3, 1) nvme0n1.dsm(qpair, buf_dsm, 3).waitdone()
- Buffer类包含length/offset/size等属性,他们的关系如下图所示。
0 offset length |===============|===================================| |<========= size =========>|
length是内存的物理长度,但实际用来存放数据的内存是从offset开始的size大小的内存。默认情况下offset=0,size=length。根据测试需要,脚本可以调整buffer对象的offset和size,以构造出不同的PRP和SGL。需要注意的是,offset+size必须小于等于length,否则可能会产生内存越界访问。
def test_prp_page_offset(nvme0n1, qpair): read_buf = Buffer(512+3) read_buf.offset = 3 read_buf.size = 512 nvme0n1.read(qpair, read_buf, 0, 1).waitdone()
- Buffer用于HMB。HMB是系统预留的一部分内存,这些内存空间完全由测试盘使用。Buffer对象申请到的物理内存空间可以用于HMB,但需要特别注意这些Buffer对象在HMB存在的时候不能被释放,否则HMB的内存空间会被回收,并被Python用来存放其他对象,造成HMB空间的数据可能被篡改。PyNVMe3提供了HMB库(scripts/hmb.py)以及测试脚本(scripts/conformance/03_features/hmb)。
- Buffer用于CMB。CMB(Controller Memory Buffer)是NVMe盘中一片被映射到BAR空间的系统可读写的内存区域,用于存放PRP/SGL,IOCQ/IOSQ,甚至用户数据。Buffer对象可以从CMB空间中获得内存,并用于创建IOSQ。
def test_cmb_sqs_single_cmd(nvme0): cmb_buf = Buffer(10*64, nvme=nvme0) cq = IOCQ(nvme0, 1, 10, PRP(10*16)) sq = IOSQ(nvme0, 1, 10, cmb_buf, cq=cq)
- Buffer用于SGL测试。脚本可以配置Buffer的sgl属性,这样驱动会在SQE中产生SGL来指向这片内存区域。
def test_sgl_buffer(nvme0n1, qpair, buf): buf.sgl = True nvme0n1.read(qpair, buf, 0).waitdone()
- PyNVMe3从Buffer类继承出SegmentSGL,LastSegmentSGL,DataBlockSGL,BitBucketSGL等用于构造各种不同的SGL Descriptor。下面这个脚本实现了NVMe Spec中的SGL示例。 该示例的数据总长度为13KB(26个LBA),分成3段SGL:
- seg0: 包含一段3KB的内存块,并指向seg1;
- seg1: 包含一段4KB的内存块,以及一段2KB的空洞,并指向seg2;
- seg2: 是最后一个SGL,包含一段4KB的内存块。
具体内存的布局以及对应的PyNVMe3脚本如下:
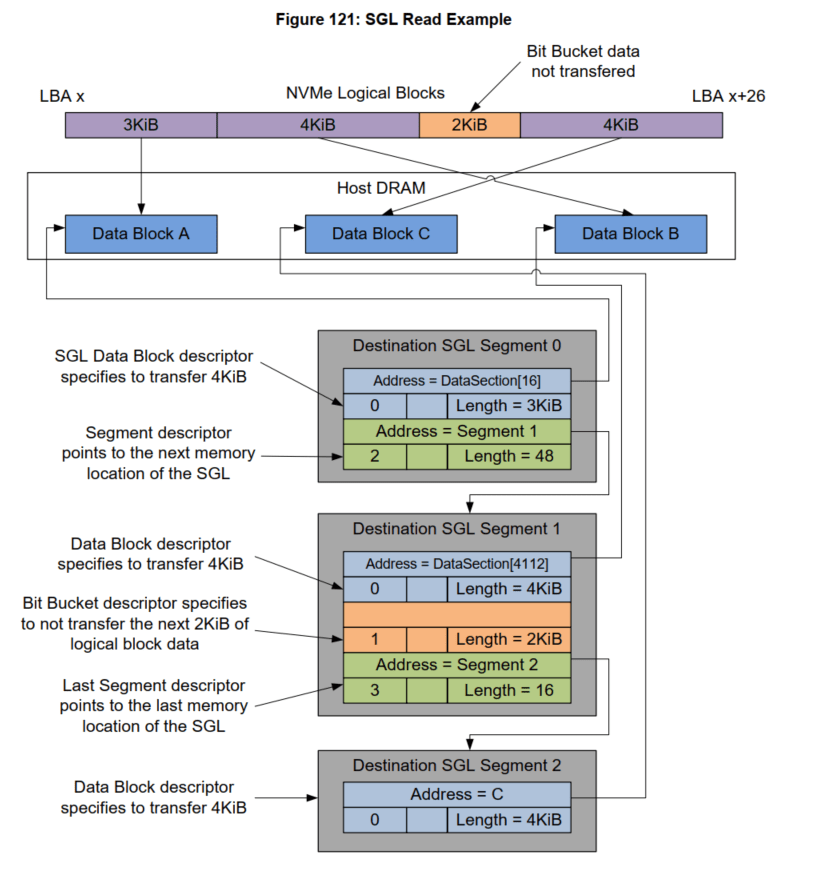
def test_sgl_segment_example(nvme0, nvme0n1): sector_size = nvme0n1.sector_size cq = IOCQ(nvme0, 1, 10, PRP(10*16)) sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq) sseg0 = SegmentSGL(16*2) sseg1 = SegmentSGL(16*3) sseg2 = LastSegmentSGL(16) sseg0[0] = DataBlockSGL(sector_size*6) sseg0[1] = sseg1 sseg1[0] = DataBlockSGL(sector_size*8) sseg1[1] = BitBucketSGL(sector_size*4) sseg1[2] = sseg2 sseg2[0] = DataBlockSGL(sector_size*8) sq.read(cid=0, nsid=1, lba=100, lba_count=26, sgl=sseg0) sq.tail = sq.wpointer cq.waitdone(1) cq.head = cq.rpointer sq.delete() cq.delete()
- 在Buffer初始化的时候,可以通过ptype/pvalue参数指定数据的pattern,默认为全零数据。
- 脚本可以使用数组下标的方式来读写buffer里面的每一个字节,也可以通过dump()方法在日志中打印buffer的数据。当需要从buffer中提取某个字段,可以使用data方法,指定字段的首尾地址,以及数据的类型(默认为int,也可以指定为str)。data方法主要用于解析盘返回的数据结构,譬如identify数据。
buf = Buffer(4096, ptype=0xbeef, pvalue=100) logging.info(buf.dump(64)) logging.info(buf[0]) logging.info(buf.data(1, 0))
- 脚本也可以直接使用==或者!=运算符来比较两个buffer的数据。譬如:buf1 == buf2。
- 脚本可以获取buffer对象内存空间的物理地址。这个物理地址并不是buffer对象内存的0地址,而是offset处的地址。我们可以通过修改offset,可以产生不同offset的PRP。
logging.info(buf.phys_addr)
从上面这些例子可以看到,Buffer对象在不同场景中被频繁用到,让脚本可以在共享内存这个基础上面构造各种NVMe测试,比单纯通过API提供的测试能力具有更高的可扩展性。
Pcie
NVMe协议基于PCIe协议,所以一个NVMe测试盘首先是一个PCIe设备。PyNVMe3可以在测试盘上创建一个Pcie对象,并且提供了一些PCIe层面的测试能力。
- 读写PCIe配置空间。通过下标访问或者API可以读写PCIe设备的配置空间。
- 查找capability。通过cap_offset()方法可以找到指定的capability在配置空间里面的偏移地址。
- hot reset和FLR reset。通过reset()和flr()可以对盘做PCIe设备层面的reset。这些reset之后,需要再次调用Controller.reset()才能找回NVMe设备。
def test_pcie_flr_reset(pcie, nvme0): pcie.flr() nvme0.reset()
- 读写BAR0空间。通过一组API,脚本可以读写BAR0空间的寄存器。
def test_bar0_access(pcie, nvme0): assert pcie.mem_qword_read(0) == nvme0.cap
- 一些可读写的PCIe属性:
- speed,用来获取或修改PCIe的速度(Gen1-5)。
- aspm, 用来获取或修改ASPM的设置。
- power_state,用来获取或修改PCIe设备的电源状态,譬如D3hot。
提供PCIe类最重要的意义在于我们可以在脚本(而非驱动)里面实现对NVMe设备的初始化过程。当在项目初期很多功能还不完善的时候,标准内核驱动可能无法初始化NVMe设备,也就无法开展后续测试。但PyNVMe3的测试脚本可以修改NVMe初始化过程,后续测试工作就可以顺利进行。
Controller
在Pcie对象的基础上,PyNVMe3可以创建Controller对象。NVMe协议分开定义了Controller和Namespace,因此PyNVMe3也分别提供了Controller类和Namespace类。脚本可以创建多个Controller对象,以满足多设备、多端口、SRIOV等测试的需要。下面我们分别介绍Controller类和Namespace类。
admin命令的发送和回收
Controller类主要用于发送admin命令,PyNVMe3为大部分admin命令都提供了API接口,并且还提供Controller.send_cmd()这个通用接口来发送VU命令。
def test_admin_cmd(nvme0, buf): nvme0.getlogpage(2, buf, 512).waitdone() nvme0.send_cmd(0xa, nsid=1, cdw10=7).waitdone()
命令的发送是一个异步操作,我们可以通过Controller.waitdone()等待其完成。脚本可以为每个命令指定一个回调函数。命令完成后,PyNVMe3的驱动会调用这条命令的回调函数,用来处理盘返回的CQE。需要注意的是在回调函数内不可以再使用Controller.waitdone()。下面是一个identify命令的回调函数的例子。
def test_callback_identify(nvme0, buf): status = 0 def identify_cb(cpl): nonlocal status status = cpl[3] >> 17 logging.info("identify done") nvme0.identify(buf, cb=identify_cb).waitdone()
NVMe协议要求admin命令完成必须要有中断,所以waitdone在检查admin CQ之前会先检查中断信号。如果没有中断信号,waitdone不会返回。IO命令没有这样的要求和操作。脚本在调用waitdone方法的时候可以设置interrupt_enabled=False来跳过对admin CQ的中断检查。
很多时候测试脚本需要获取CQE里面的dword0字段,waitdone()函数提供了这样的便利,会直接返回最后一条admin命令的CQE的dword0。譬如下面的脚本,不需要使用回调函数就可以获得CQE的dword0。
def test_get_num_of_queue(nvme0): cdw0 = nvme0.getfeatures(7).waitdone() num_of_queue = (cdw0&0xffff) + 1
Controller对象还提供最后一条admin命令的cid和latency(以us为单位)。
def test_latest_cid_latency(nvme0): nvme0.format().waitdone() logging.info("latest cid: %d"%nvme0.latest_cid) logging.info("latest command latency: %d"%nvme0.latest_latency)
AER是一种特殊的admin命令,系统发出AER命令后,盘并不会立刻返回CQE。要等到某些约定的事件发生,盘才会返回CQE给系统,并附带具体的事件信息。AER命令不受timeout限制,但是可以abort。PyNVMe3的脚本在发出AER命令之后,不需要为AER命令添加waitdone操作,因为我们也不知道其CQE会在什么时候出现。在其他命令的waitdone过程中如果发现AER的CQE,PyNVMe3会抛出warning通知脚本AER返回,并且补发一条AER,然后waitdone继续等待其他命令的完成。所以在期望有AER产生的地方,脚本需要发一条辅助的admin命令,借用其waitdone来捕获AER的CQE。
def test_sq_doorbell_invalid(nvme0, tail, buf): cq = IOCQ(nvme0, 1, 10, PRP()) sq = IOSQ(nvme0, 1, 10, PRP(), cq=cq) with pytest.warns(UserWarning, match="AER notification is triggered: 0x10100"): sq.tail = 10 time.sleep(0.1) nvme0.getfeatures(7).waitdone() # 辅助命令,用来捕获AER的CQE sq.delete() cq.delete()
Controller常用方法
除了admin命令,Controller类还提供了一些常用的方法,譬如用downfw()来更新固件。因为这些API不是单纯的admin命令,所以后面不需要调用waitdone()。下面是一些比较常用的方法。
- Controller.downfw(): 用于升级SSD固件。
- Controller.reset(): 发起Controller reset,包括用户可定义的NVMe初始化过程。
def test_admin_func(nvme0): nvme0.downfw('path/firmware_image_file.bin') nvme0.reset()
- Controller.get_lba_format()方法需要提供LBA大小的参数,返回对应的LBA Format id。
def test_get_lba_format(nvme0, nvme0n1): fid = nvme0.get_lba_format(data_size=512, meta_size=0, nsid=1)
- Controller.supports()用于判断SSD是否支持某个admin命令,如果支持则返回True。
def test_controller_support_format(nvme0): if nvme0.supports(0x80): nvme0.format().waitdone()
- Controller.timestamp()可以获取当前盘的时间戳。
def test_timestamp(nvme0): logging.info("currect timestamp: %s"%nvme0.timestamp())
- Controller.iostat()可以获取当前的性能.
- 为了进一步方便用户写脚本,PyNVMe3提供了一个便捷的获取identify数据的fixture,使用方式如下:
def test_identify(id_ctrl, id_ns): logging.info(id_ctrl.VID) logging.info(id_ctrl.SN) logging.info(id_ns.NSZE) logging.info(id_ns.NCAP)
id_ctrl是Controller identify数据,id_ns是Namespace identify数据。identify数据的字段名字和NVMe协议文本一致。
timeout超时的配置
PyNVMe3可以配置命令的timeout时间,默认为10秒。命令超时之后,PyNVMe3驱动会抛出warning,并在这条命令的CQE中标记error code为07/ff。
脚本也可以单独更改某一种命令的timeout时间,譬如format命令通常需要比较长的时间才能完成,脚本可以单独修改其timeout时间。下面的例子中nvme0.timeout修改的是全局的timeout时间,单位都是毫秒。
def test_timeout_format(nvme0): nvme0.timeout=10000 #10s nvme0.get_timeout_ms(opcode=0x80) nvme0.set_timeout_ms(opcode=0x80, msec=30000)
调用Namespace.set_timeout_ms()方法可以配置IO命令的timeout时间。每次Controller reset之后,所有命令的timeout时间会恢复到默认的10秒。
cmdlog命令日志
PyNVMe3支持获取最近的若干命令的日志。Controller.cmdlog()用来获取admin队列的命令日志,Controller.cmdlog_megrged()用来获取测试盘所有队列的命令日志,按发送时间逆序排序。
def test_command_log(nvme0): for c in nvme0.cmdlog_merged(100): #所有队列的命令日志 logging.info(c) for c in nvme0.cmdlog(10): # admin队列的命令日志 logging.info(c)
cmdlog的打印格式如下,包含完整的SQE和CQE数据,以及命令发送和完成的时间戳。PyNVMe3在VSCode下的插件也可以看到同样的命令日志,供脚本调试使用。
2022-10-08 17:47:28.954447 [cmd000033: Identify, sqid: 0] 0x007e0006, 0x00000002, 0x00000000, 0x00000000 0x00000000, 0x00000000, 0x26cbe000, 0x00000000 0x00000000, 0x00000000, 0x00000000, 0x00000000 0x00000000, 0x00000000, 0x00000000, 0x00000000 2022-10-08 17:47:28.954568 [cpl: SUCCESS] 0x00000000, 0x00000000, 0x00000003, 0x0001007e 2022-10-08 17:47:28.954312 [cmd000034: Identify, sqid: 0] 0x007e0006, 0x00000001, 0x00000000, 0x00000000 0x00000000, 0x00000000, 0x26cbe000, 0x00000000 0x00000000, 0x00000000, 0x00000000, 0x00000000 0x00000000, 0x00000000, 0x00000000, 0x00000000 2022-10-08 17:47:28.954436 [cpl: SUCCESS] 0x00000000, 0x00000000, 0x00000002, 0x0001007e 2022-10-08 17:47:28.954082 [cmd000035: Identify, sqid: 0] 0x007e0006, 0x00000000, 0x00000000, 0x00000000 0x00000000, 0x00000000, 0x26cfe000, 0x00000000 0x00000000, 0x00000000, 0x00000001, 0x00000000 0x00000000, 0x00000000, 0x00000000, 0x00000000 2022-10-08 17:47:28.954231 [cpl: SUCCESS] 0x00000000, 0x00000000, 0x00000001, 0x0001007e
MDTS
NVMe盘可以声明其支持最大的传输数据大小Max Data Transfer Size (MDTS)。PyNVMe3的NVMe驱动最大支持2MB MDTS,当测试数据的大小超过2MB时,需要使用metamode方式来写脚本。脚本可以通过Controller.mdts获取MDTS值。下面的例子中,脚本尝试发送一个读命令,其数据长度超过了MDTS,所以盘将会返回error。
def test_read_invalid_number_blocks(nvme0, nvme0n1, qpair): mdts = nvme0.mdts//nvme0n1.sector_size buf = Buffer((mdts+1)*nvme0n1.sector_size) nvme0n1.read(qpair, buf, 0, mdts+1).waitdone()
Namespace命令
PyNVMe3支持多Namespace的测试,并提供相关命令的API,譬如Namespace Attachment和Management命令。为了方便测试脚本使用,PyNVMe3提供还了ns_attach, ns_detach, ns_create, ns_delete等常用方法。
def test_namespace_detach_and_delete(nvme0, nvme0n1): cntlid = nvme0.id_data(79, 78) nvme0.ns_detach(1, cntlid) nvme0.ns_delete(1)
Security命令
PyNVMe3也支持security_send和security_receive命令,并且提供完整的TCG测试脚本。
NVMe初始化
上文PCIe类中我们提到NVMe初始化过程可以通过脚本来实现。通常NVMe设备的初始化由驱动程序实现,但PyNVMe3可以让测试脚本来定义NVMe设备初始化的具体过程。脚本也可以不提供NVMe初始化过程,让PyNVMe3的NVMe驱动负责初始化。下面是一段标准的NVMe初始化过程。
def nvme_init_user_defined(nvme0): # 1. disable cc.en nvme0[0x14] = 0 # 2. and wait csts.rdy to 0 nvme0.wait_csts(rdy=False) # 3. set admin queue registers if nvme0.init_adminq() < 0: raise NvmeEnumerateError("fail to init admin queue") # 4. set register cc nvme0[0x14] = 0x00460000 # 5. enable cc.en nvme0[0x14] = 0x00460001 # 6. wait csts.rdy to 1 nvme0.wait_csts(rdy=True) # 7. identify controller and all namespaces nvme0.identify(Buffer(4096)).waitdone() if nvme0.init_ns() < 0: raise NvmeEnumerateError("retry init namespaces failed") # 8. set/get num of queues nvme0.setfeatures(0x7, cdw11=0xfffefffe, nsid=0).waitdone() cdw0 = nvme0.getfeatures(0x7, nsid=0).waitdone() nvme0.init_queues(cdw0) # 9. send out all AER commands aerl = nvme0.id_data(259)+1 for i in range(aerl): nvme0.aer() def test_user_defined_nvme_init(pcie): nvme0 = Controller(pcie, nvme_init_func=nvme_init_user_defined)
测试脚本可以根据测试需要,修改上面NVMe初始化的流程和参数。注意:错误的初始化脚本可能会使得驱动或盘无法工作。
Lazy Doorbell
PyNVMe3支持在初始化Admin队列时指定更新Doorbell的策略。默认情况下,PyNVMe3的NVMe驱动在每发出一个admin命令后会立刻更新Doorbell。但是,当我们设置lazy_doorbell为True时,驱动会在waitdone()时才更新Doorbell。例如下面的脚本,在初始化NVMe过程中指定init_adminq的参数lazy_doorbell=True,后面连续发出3条getfeatures命令,但Doorbell只在最后waitdone(3)的时候被更新到tail的位置。
def test_ring_admin_queue_doorbell(nvme0): def nvme_init_admin_lazy_doorbell(nvme0): # 1. disable cc.en nvme0[0x14] = 0 # 2. and wait csts.rdy to 0 nvme0.wait_csts(rdy=False) # 3. set admin queue registers if nvme0.init_adminq(lazy_doorbell=True) < 0: raise NvmeEnumerateError("fail to init admin queue") # 4. set register cc nvme0[0x14] = 0x00460000 # 5. enable cc.en nvme0[0x14] = 0x00460001 # 6. wait csts.rdy to 1 nvme0.wait_csts(rdy=True) # 7. identify controller and all namespaces nvme0.identify(Buffer(4096)).waitdone() if nvme0.init_ns() < 0: raise NvmeEnumerateError("retry init namespaces failed") # 8. set/get num of queues nvme0.setfeatures(0x7, cdw11=0xfffefffe, nsid=0).waitdone() cdw0 = nvme0.getfeatures(0x7, nsid=0).waitdone() nvme0.init_queues(cdw0) # use the user defined nvme init function to reset the controller nvme0.nvme_init_func = nvme_init_admin_lazy_doorbell nvme0.reset() nvme0.getfeatures(7) nvme0.getfeatures(7) nvme0.getfeatures(7) nvme0.waitdone(3)
通过上述各种API接口,用户可以灵活实现测试脚本,对测试盘进行全方位的测试。API接口的具体使用说明可以在VSCode的联机帮助文档中获得。
Namespace
PyNVMe3在创建Namespace对象时需要将其关联到一个Controller对象上面,在测试结束后需要关闭Namespace对象。
nvme0n1 = Namespace(nvme0) nvme0n1.close()
如果使用PyNVMe3提供的fixture nvme0n1,pytest会在测试结束的时候自动释放这个Namespace对象。
IO命令
通过Namespace对象,脚本可以发送各种IO命令,使用方法和Controller对象中的admin命令类似,同样具有回调、timeout时间设置等功能。在发出命令之后也需要通过waitdone()来回收命令。下面是一个写数据到LBA0的例子。其他发送命令的细节不在这里赘述,可以参考Controller对象发送admin命令的部分。
def test_write(nvme0n1, qpair, buf) nvme0n1.write(qpair, data_buf, 0).waitdone()
Namespace常用方法
除了IO命令,Namespace类还提供了一些常用的方法,譬如用Namespace.format()做格式化操作。这些API不是单纯的IO命令,所以后面不需要调用waitdone()。下面是一些比较常用的方法。
- format: 对当前namespace做格式化,会调整timeout时间,并等待格式化完成。建议在测试脚本中,如果不是在针对format命令做测试,尽量使用Namespace.format()来做格式化操作。默认会保留当前的LBA Format配置。
def test_namespace_format(nvme0n1): nvme0n1.format()
- supports, set_timeout_ms, get_lba_format: 这些API的用法和Controller类中的同名API相同。
- PyNVMe3支持ZNS命令集,并提供了大量测试脚本。
- namespace Identify data中的字段可以通过fixture id_ns获取,字段名字使用NVMe协议文本中的大写缩写形式。
- Namespace对象也提供了一些常用的只读属性,譬如:nsid, capacity, sector_size等。
数据校验
PyNVMe3提供了丰富的功能,极高的性能,但我们更重视对数据一致性的测试能力。数据一致性是存储的基本需求,所以数据一致性不应该是某一个测试项目,而应该是所有测试项目都必需的检查点。PyNVMe3提供了对用户脚本透明的数据一致性的检查能力。如下面这段脚本:
def test_write_read(nvme0n1, qpair, buf, verify): nvme0n1.write(qpair, buf, 0).waitdone() nvme0n1.read(qpair, buf, 0).waitdone()
这段脚本先写LBA0,然后读LBA0。PyNVMe3驱动在读到LBA0的数据之后,会立刻检查数据的正确性,是不是和刚才写下去的数据一样。脚本唯一需要做的就是在测试函数的参数列表里面加上verify这个fixture。我们建议除性能测试以外的其他所有测试项目都尽量要加上verify这个fixture。
这里的verify fixture和NVMe协议中定义的Verify命令没有任何关系。PyNVMe3通过crc校验来检查数据的一致性:在写命令结束的时候,为每一个LBA的数据生成一个CRC值存放在系统内存中;在读命令结束的时候,再次计算读到数据的CRC值,并和系统内存中对应LBA记录的CRC值做比较。每个LBA需要一个字节来记录CRC值,并且使用大页内存来保存CRC值。以512字节LBA为例,一个4T的盘大概需要8G的内存来存放CRC,所以我们在建立运行时环境的时候需要通过make setup来预留足够的大页内存。
在Namespace对象初始化期间,PyNVMe3会为CRC分配内存,如果没有足够内存,PyNVMe3会在日志中记录warning信息,数据校验功能被关闭,但测试可以继续执行。另外一种方式,可以在初始化Namespace对象时,通过nlba_verify来限制CRC校验的范围,这样在调试脚本时可以不受系统内存大小的限制。但在正式执行测试的时候,我们建议全盘校验CRC,这也是PyNVMe3的默认行为。
数据校验功能对ns.cmd和ioworker发出的IO都有效,包括读写命令,也包括其他会改变media数据的命令,譬如Trim和Format等。下面这段脚本用不同方式写数据,最后用ioworker读数据,所有数据都会进行CRC校验。
def test_verify(nvme0n1, verify): # write data nvme0n1.ioworker(io_size=8, lba_random=False, read_percentage=0, qdepth=2, io_count=1000).start().close() nvme0n1.write(qpair, buf, 0).waitdone() # verify data nvme0n1.ioworker(io_size=8, lba_random=False, read_percentage=100, io_count=1000).start().close()
除了CRC检验,我们还需要构造一些特殊的数据内容才能更好地发现SSD的潜在问题。譬如,假设我们一直用全0数据写所有LBA,那即便不同LBA数据映射有问题,CRC校验也无法检查出来。所以,PyNVMe3默认会在每个LBA数据的开头8字节填入(nsid, LBA)值,保证在空间上所有的数据都是不同的。
更进一步,假设我们一直在写同一个LBA,但可能会因为数据版本错误拿到历史上的旧数据。为此,PyNVMe3在每个LBA的结尾8字节(不包含metadata)自动填入一个token。这个token是从0递增的一个数字,保证每次写的数据内容在时间轴上也是不同的。
但有些场景下,用户脚本不希望头尾数据被修改,这时可以通过Namespace.inject_write_buffer_disable()关闭这个功能,但这不会影响CRC的记录和检查,CRC校验功能依然有效。
CRC数据存放在内存中,测试结束后CRC值就会丢失。脚本可以通过save_crc()这个API导出CRC数据到一个指定的文件,并在其他测试中,通过load_crc()这个API从指定文件中导入CRC。这样我们可以实现CRC数据的持久化,从而在retention测试中做数据校验。
NVMe协议使用异步的工作方式,所以IO之间的顺序是无法保证的。这样先后对同一个LBA的多笔写操作就无法保证最终的数据内容,读写混合的操作也无法确切地知道读数据的正确版本。为此我们引入了LBA锁:在发出每一个IO之前,会检查其所有LBA,当有任何LBA被锁,我们就不会发出这个IO。如果可以发出IO,我们会对其所有LBA上锁;IO完成后解锁。这样可以确保同一个LBA在某一时刻只有一个IO在操作。
这种LBA锁机制只在进程内有效,进程间的锁机制代价太大,所以不做实现。当有2个ioworker读写同一个LBA,这时我们无法知道最终数据的内容,所以可能会出现CRC误报。脚本可以对不同的ioworker划分不同的LBA空间,来避免出现上述场景。或者作为一种特别的压力测试,在这类脚本中关闭数据校验功能。
CRC和LBA锁不仅适用于读写命令,也适用于其他所有能够访问存储介质的命令,譬如format/sanitize/trim/append等。需要注意的是,当trim覆盖一个很大的LBA范围时,很有可能会因为LBA锁而被block,同时需要更多时间来更新LBA锁和CRC。当实现类似的测试时,建议限制Namespace的校验范围。
Qpair
使用Controller对象我们可以发出admin命令,使用Namespace对象我们可以发送io命令。但不同的是,发送IO命令需要通过Qpair对象,也就是通过某个IO Queue来发出IO命令。
在PyNVMe3中,我们将提交队列SQ和完成队列CQ组合为Qpair。admin Qpair隐藏在Controller对象中,并且在NVMe初始化时被创建。IO Qpair可以通过Qpair类创建。在创建qpair对象时,脚本可以指定队列深度等参数。
测试完成后,脚本必须通过调用Qpair.delete()来删除SQ和CQ。下面例子创建一个队列深度为16的qpair,并删除qpair。
def test_qpair(nvme0): qpair = Qpair(nvme0, depth=16) qpair.delete()
如果使用fixture qpair,PyNVMe3会在测试结束时自动调用delete方法。这也是我们推荐的脚本写法。例子如下:
def test_write_read(nvme0n1, qpair, buf): nvme0n1.write(qpair, buf, 0).waitdone()
初始化参数
与admin命令类似,PyNVMe3支持在初始化Qpair时指定更新Doorbell的策略。默认情况下,PyNVMe3的驱动在每发出一个IO命令后会立刻更新Doorbell。但是,当我们设置lazy_doorbell为True时,驱动会在waitdone()时才更新Doorbell。例如下面的脚本,在创建qpair过程中指定参数lazy_doorbell=True,后面连续发出3条read命令,但Doorbell只在最后waitdone(3)的时候被更新一次。
def test_ioworker_with_qpair_performance(nvme0, nvme0n1, buf): qpair = Qpair(nvme0, 1024, ien=False, lazy_doorbell=True) nvme0n1.read(qpair, buf, 0) nvme0n1.read(qpair, buf, 0) nvme0n1.read(qpair, buf, 0) qpair.waitdone(3) qpair.delete()
PyNVMe3在创建Qpair时,会申请内存用做SQ和CQ队列。Qpair也支持脚本创建SQ和CQ的buffer,以为覆盖更多的测试用例。譬如脚本可以在CMB上面建立SQ。
PyNVMe3在创建Qpair时也可以通过参数prio指定SQ的优先级,用于实现Weighted Round Robin仲裁方式的测试。
Qpair常用方法
Controller对象的cmdlog_merged()方法可以获取所有队列的命令日志。如果我们只需要拿到某一个IO Queue的命令日志,可以使用Qpair对象的cmdlog()方法。
def test_qpair_cmdlog(nvme0n1, qpair): nvme0n1.flush(qpair).waitdone() for c in qpair.cmdlog(1): logging.info(c)
常用属性
Qpair对象提供以下常用的属性:
- latest_cid:最近发送IO命令的CID。
- latest_latency:最近发送IO命令的延迟。
- prio:队列的优先级。
- sqid:队列的sqid。
中断检查
PyNVMe3支持中断相关的测试,通过NVMe驱动实现的中断控制器,可以让脚本来配置并检查中断信号。在创建Qpair对象时,可以使能CQ的中断(默认开启), 并指定中断向量号。脚本使用Qpair中的一组中断相关的API来检查中断信号。
- qpair.msix_clear()用于清除当前qpair上所有MSI-X中断信号。
- qpair.msix_isset()返回bool值,用于检查对应CQ上当前是否有中断信号。
- qpair.wait_msix()用于等待当前qpair的中断信号。
- qpair.msix_mask()用于mask qpair的中断信号。
- qpair.msix_unmask()用于unmask qpair的中断信号。
下面是一个示例,测试中断屏蔽的功能。
def test_interrupt_qpair_msix_mask(nvme0, nvme0n1, buf, qpair): # create a pair of CQ/SQ and clear MSIx interrupt qpair.msix_clear() assert not qpair.msix_isset() # send a read command nvme0n1.read(qpair, buf, 0, 8) time.sleep(0.1) # check if the MSIx interrupt is set up assert qpair.msix_isset() qpair.waitdone() # clear MSIx interrupt and mask it qpair.msix_clear() qpair.msix_mask() assert not qpair.msix_isset() # send a read command nvme0n1.read(qpair, buf, 0, 8) # check if the MSIx interrupt is NOT set up time.sleep(0.2) assert not qpair.msix_isset() # unmask the MSIx interrupt qpair.msix_unmask() qpair.waitdone() time.sleep(0.1) # check if the MSIx interrupt is set up assert qpair.msix_isset()
PyNVMe3支持中断相关的测试,但PyNVMe3并不依赖于中断。脚本可以主动通过调用waitdone()来回收IO命令。
Subsystem
PyNVMe3的Subsystem对象主要提供reset和power相关的方法:
- Subsystem.reset()实现了subsystem reset。
- Subsystem.poweron()实现测试盘电源上电。
- Subsystem.poweroff()实现测试盘电源掉电。
默认情况下,poweroff由系统的S3电源模式实现,poweron由RTC实现。为了提高测试效率,我们还可以使用各种掉电测试治具提供的电源开关操作。PyNVMe3在scripts/pam.py中实现了对Quarch PAM设备的支持,并提供上电和下电操作的接口函数。
在subsystem初始化的时候,可以将上电和下电操作的接口函数注册给subsystem对象。这样在脚本中调用subsystem.poweron()和subsystem.poweroff()就会间接调用PAM设备提供的上电和下电操作,而非S3和RTC。
@pytest.fixture(scope="function") def subsystem(nvme0, pam): if pam.exists(): # use PAM to control power on off ret = Subsystem(nvme0, pam.on, pam.off) else: # use S3 to control power on off ret = Subsystem(nvme0) return ret
除此之外,PyNVMe3驱动内部完成了上电和下电过程中的设备扫描以及驱动绑定等操作,脚本只需要在poweron()之后调用Controller.reset()就能继续操作NVMe设备。用户可以仿照pam.py来适配其他电源测试治具,只需要修改Python脚本而无需修改NVMe驱动。测试脚本只需要引用subsystem就可以控制上下电,而不需要知道具体使用哪种掉电设备。
通过以上部分介绍,我们可以使用Namespace, Qpair, Buffer来发出任何IO命令,这是常规测试脚本可以使用的方式。如果需要更高的性能,可以使用ioworker;如果需要更高的测试覆盖率,可以使用metamode。下面我们继续介绍这两种收发IO的方式。
IOWorker
借助ioworker我们可以打出比fio更大的IO压力,实现各种不同特性的测试需求,譬如SGL、ZNS等。PyNVMe3还可以在ioworker运行的过程中用脚本定义其他操作,如power cycle,reset和各种命令。这样脚本可以实现更加复杂的测试场景。每一个ioworker会创建一个独立的子进程用来收发IO,并且会自行创建qpair,测试结束后自行删除。
为了更好的利用IOWorker,下面将逐个介绍IOWorker的参数,并举例演示。默认情况下ioworker进行全盘4k随机读测试,测试脚本并不需要定义每一个参数,因为参数的默认值对大部分测试都是合理的。ioworker的参数除了qpair,其他所有参数都要求传入关键字来定义。
io_size
io_size定义每个IO的大小,是以LBA为单位计算的,默认是8个LBA。它可以是一个固定的大小,或者有多个大小的列表。如果不同大小的IO所占的比例不是均匀分布的,则需要以字典的形式,在字典中指定比率。
下面的脚本演示了,对于512Byte LBA的SSD发送,4k IO随机读;4K, 8k, 128k IO均匀混合随机读;4k占比50%,8k占比25%,128k占比25% IO随机读。
def test_ioworker_io_size(nvme0n1): nvme0n1.ioworker(io_size=8, time=5).start().close() nvme0n1.ioworker(io_size=[8, 16, 256], time=5).start().close() nvme0n1.ioworker(io_size={8:50, 16:25, 256:25}, time=5).start().close()
time
控制ioworker的运行时间,以秒为单位。下面是一个ioworker运行5秒的例子。
def test_ioworker_time(nvme0n1): nvme0n1.ioworker(time=5).start().close()
io_count
指定要发送的IO个数。默认值为0,表示无限制。io_count和time需要指定其中一种,当同时存在时,任意一个条件满足,ioworker就会结束。下面的例子演示了通过ioworker发送10000个IO.
def test_ioworker_io_count(nvme0n1): nvme0n1.ioworker(io_count=10000).start().close()
lba_random
lba_random可以指定随机IO的比例,默认为True,全部随机。lba_random传入数字时,设定的就是随机IO的比例。下面的例子演示了顺序的IO和50%随机的IO两种场景。
def test_ioworker_lba_random(nvme0n1): nvme0n1.ioworker(lba_random=False, time=5).start().close() nvme0n1.ioworker(lba_random=50, time=5).start().close()
lba_start
指定第一个命令的LBA地址。默认值为0,表示从region_start开始。region_start是ioworker的另外一个参数,下文会介绍。下面是ioworker从LBA 0x10开始,每个IO为一个LBA的大小,反向顺序读的例子。
def test_ioworker_lba_start(nvme0n1): nvme0n1.ioworker(lba_start=0x10, lba_random=False, lba_step=-1, io_size=1, time=5).start().close()
lba_step
lba_step只有在顺序读写中才可以使用,在顺序读写中起始LBA会随着lba_step大小增加,跳转着读写LBA。lba_step的大小与io_size一样也是以LBA为单位定义的。下面的例子演示了IO大小4k顺序读,每个IO间隔4k的例子。
def test_ioworker_lba_step(nvme0n1): nvme0n1.ioworker(io_size=8, lba_random=False, lba_step=16, time=5).start().close()
有了lba_step,ioworker不仅可以在正向顺序读写,也可以反向的顺序读写,只需要设置为负数即可。下面的例子演示了如何反向顺序读, 例子中的ioworker会对LBA 10,9,8,7,6,5,4,3,2,1的顺序依次发送read命令。
def test_ioworker_lba_step(nvme0n1): nvme0n1.ioworker(lba_random=False, io_size=1, lba_start=10, lba_step=-1, io_count=10).start().close()
当lba_step设置成0时,ioworker可以对指定的LBA反复读写。
def test_ioworker_lba_step(nvme0n1): nvme0n1.ioworker(lba_random=False, lba_start=100, lba_step=0, time=5).start().close()
read_percentage
指定IO读写的比例,0意味着全是write,100意味着全是read。默认为100。 以下是一个读写各占50%的例子。
def test_ioworker_read_percentage(nvme0n1): nvme0n1.ioworker(read_percentage=50, time=5).start().close()
op_percentage
以字典的形式指定ioworker中发送的命令的opcode及其占比。当op_percentage和read_percenfage同时存在时,以op_percentage为准。以下是一个read命令占40%,write命令占30%,trim命令占30%的例子。
def test_ioworker_op_percentage(nvme0n1): nvme0n1.ioworker(op_percentage={2: 40, 9: 30, 1: 30}, time=5).start().close()
sgl_percentage
指定使用SGL的比例。0表示只有PRP,100表示只有SGL。默认值为0。
下面的例子演示了设定ioworker发出的命令50%使用PRP,50%使用SGL。
def test_ioworker_sgl_percentage(nvme0n1): nvme0n1.ioworker(sgl_percentage=50, time=5).start().close()
qdepth
指定ioworker创建的Qpair的队列深度。至少为1,默认值为63。如果传入指定qpair,则忽略这个参数。下面是一个IO队列深度为127(Q的size为128)的例子。
def test_ioworker_qdepth(nvme0n1): nvme0n1.ioworker(qdepth=127, time=5).start().close()
qprio
指定ioworker创建的sq的优先级。默认值为0,采用轮询仲裁。该参数仅在仲裁机制选择为weighted round robin with urgent priority(WRR)时使用。
def test_ioworker_qprio(nvme0n1): nvme0n1.ioworker(qprio=0, time=5).start().close()
region_start
ioworker在指定的LBA区域发送IO,region_start配置这段区域的起始LBA,默认值为0。下面是一个从LBA 0x10开始发送IO的例子。
def test_ioworker_region_start(nvme0n1): nvme0n1.ioworker(region_start=0x10, time=5).start().close()
region_end
ioworker在指定的LBA区域发送IO,region_start配置这段区域的结束LBA,默认值为0xffff_ffff_ffff_ffff,全盘。region_end指定的LBA不在IO覆盖的范围。如果iocount和time都没有,但是有region_start_end,ioworker会覆盖region后结束。下面是一个在LBA 0x10到0xff范围内发送IO的例子。
def test_ioworker_region_end(nvme0n1): nvme0n1.ioworker(region_start=0x10, region_end=0x100, time=5).start().close()
iops
为了构造出不同压力下的测试场景,ioworker中iops参数可以指定最大的IOPS。指定之后ioworker限制发送IO的速度。默认值为0,表示无限制。下面是一个指定IOPS压力为12345的例子。
def test_ioworker_iops(nvme0n1): nvme0n1.ioworker(iops=12345, time=5).start().close()
io_flags
指定在ioworker中发出io命令的dword12高16位。默认值为0。以下是一个将ioworker中的io命令中FUA字段都置1的例子。
def test_ioworker_io_flags(nvme0n1): nvme0n1.ioworker(io_flags=0x4000, time=5).start().close()
distribution
调用distribution参数后,ioworker将盘容量等分成100份,所有的IO分成10000份。以list的形式表示如何将10000份IO分配到这100个不同的区域。该参数可以用来实现JEDEC耐久性测试的IO,相关信息可以参考JEDEC文档。下面这个脚本定义如下IO分布:在前面5个1%区间内各分配1000个IO,也就是前5%的区间包含了一半IO;5%-20%这15个1%区间各分配200个IO,也就是这个15%的区间包含了30%的IO;最后80%的区间包含剩下的20%。
def test_ioworker_jedec_workload(nvme0n1): distribution = [1000]*5 + [200]*15 + [25]*80 iosz_distribution = {1: 4, 2: 1, 3: 1, 4: 1, 5: 1, 6: 1, 7: 1, 8: 67, 16: 10, 32: 7, 64: 3, 128: 3} nvme0n1.ioworker(io_size=iosz_distribution, lba_random=True, qdepth=128, distribution=distribution, read_percentage=0, ptype=0xbeef, pvalue=100, time=1).start().close()
ptype and pvalue
与Buffer中ptype和pvalue的作用一致,可以指定命令的数据。默认是完全随机的buffer,不可被压缩。
def test_ioworker_pvalue(nvme0n1): nvme0n1.ioworker(ptype=32, pvalue=0x5a5a5a5a, read_percentage=0, time=5).start().close()
io_sequence
io_sequence可以指定ioworker发送的每个IO的起始LBA, LBA数量, 命令的操作符和发送时间戳(单位是us)。在列表中指定每个IO的格式,列表的形式为:[(slba, nlb, opcode, time_sent_us), …]。以下是一个通过ioworker发送读和写命令的例子。通过参数,脚本可以通过ioworker在指定的时间发送指定的IO。
def test_ioworker_pvalue(nvme0n1): nvme0n1.ioworker(io_sequence=[(0, 1, 2, 0), (0, 1, 1, 1000000)], ptype=0, pvalue=0).start().close()
slow_latency
以微秒(us)为单位,当IO延迟大于设定值时,ioworker会打印debug信息,并抛出warning。默认为1秒。以下例子中,当IO延迟大于2秒时,ioworker会显示warning信息。
def test_ioworker_slow_latency(nvme0n1): nvme0n1.ioworker(slow_latency=2000_000, time=5).start().close()
exit_on_error
当任何IO命令失败时,立即退出ioworker。默认值为True。如果希望在有IO命令失败时,继续运行ioworker,需要指定exit_on_error=False。
def test_ioworker_exit_on_error(nvme0n1): nvme0n1.ioworker(exit_on_error=True, time=5).start().close()
output_io_per_second
以列表的形式保存每秒的IO个数。默认值:None,不收集数据。下面是一个把每秒的IOPS收集在io_per_second list中的例子。
def test_ioworker_output_io_per_second(nvme0n1): io_per_second = [] nvme0n1.ioworker(output_io_per_second=io_per_second, time=5).start().close() logging.info(io_per_second)
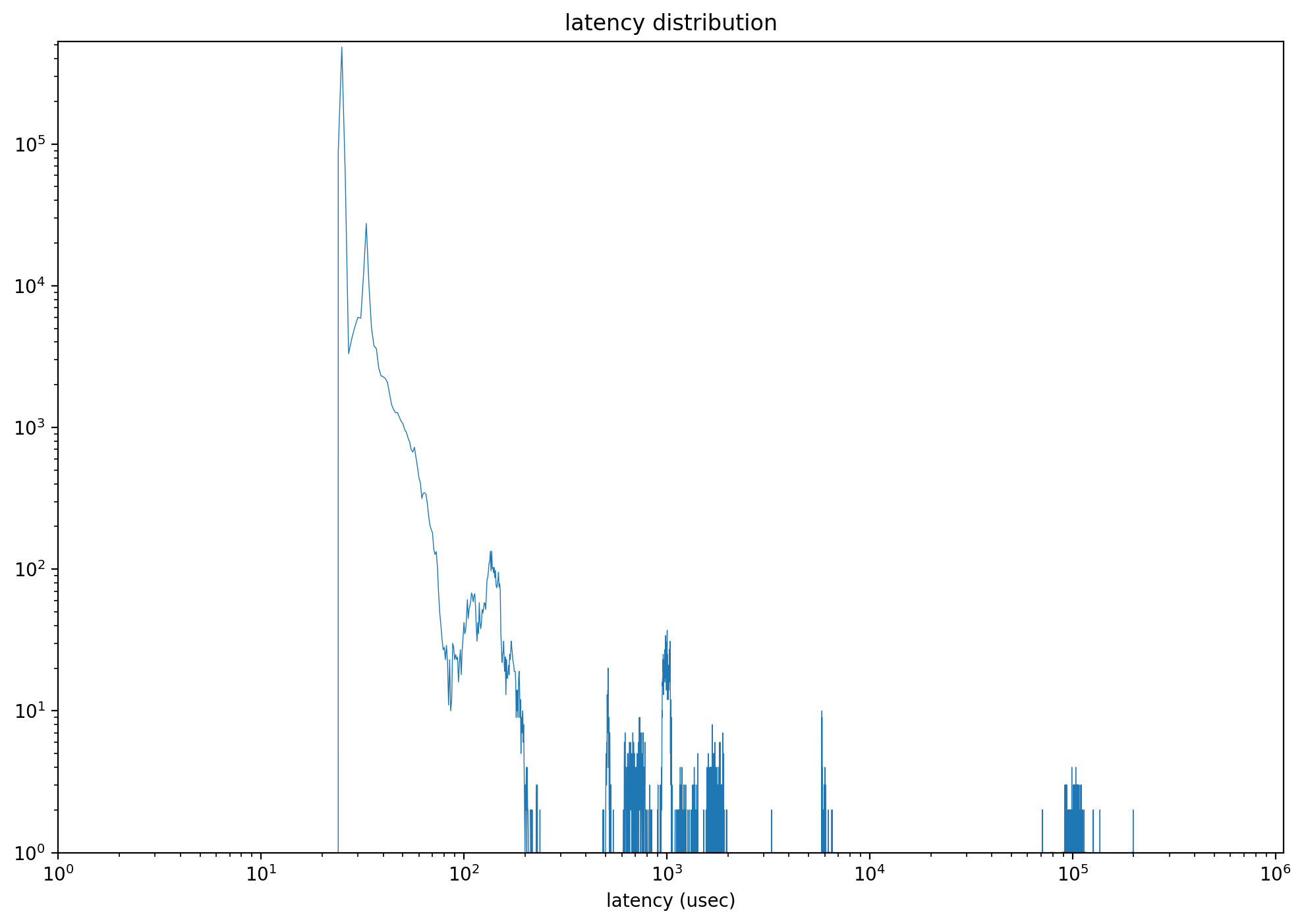
output_percentile_latency
IO延迟会很直接的影响用户的使用体验,这点在服务器使用中更加明显,ioworker通过了output_percentile_latency参数帮助收集IO延迟的相关信息。当指定了output_percentile_latency,ioworker的返回值会额外增加一个字段latency_distribution。对于延迟的结果,不仅要关注平均值,同时也要注意长尾延迟。ioworker可以以字典的形式收集在不同百分比上的IO延迟。字典键为百分比,值为以微秒(us)为单位的延迟。 默认值: None,不收集数据。下面的例子演示了收集99, 99.9, 99.999 IO延迟的数据。
def test_ioworker_output_percentile_latency(nvme0n1): percentile_latency = dict.fromkeys([99, 99.9, 99.999]) nvme0n1.ioworker(output_percentile_latency=percentile_latency, time=5).start().close() logging.info(percentile_latency)
在指定这个参数后,我们可以通过返回值里面的latency_distribution,获得每个延迟时间点上面的IO个数,从而得到如下延迟分布图。
output_percentile_latency_opcode
只跟踪指定opcode的延迟。 默认值: None,跟踪所有opcode的延迟。下面的例子演示了ioworker记录dsm命令的延迟。
def test_ioworker_output_percentile_latency_opcode(nvme0n1): percentile_latency = dict.fromkeys([99, 99.9, 99.999]) nvme0n1.ioworker(op_percentage={2: 40, 9: 30, 1: 30}, output_percentile_latency=percentile_latency, output_percentile_latency_opcode=9, time=5).start().close() logging.info(percentile_latency)
output_cmdlog_list
收集ioworker最后发送和回收的若干条命令信息。每条命令的信息包括起始LBA,LBA个数,命令操作符,发送时间戳,回收时间戳,返回状态,以元组形式记录(slba, nlb, opcode, time_sent_us, time_cplt_us, status)。默认值为None,不收集数据。下面的例子简单演示了在异步掉电测试中,收集掉电前的1000笔IO的信息。
def test_power_cycle_dirty(nvme0, nvme0n1, subsystem): cmdlog_list = [None]*1000 # 128K random write with nvme0n1.ioworker(io_size=256, lba_align=256, lba_random=True, read_percentage=30, slow_latency=2_000_000, time=15, qdepth=63, output_cmdlog_list=cmdlog_list): # sudden power loss before the ioworker end time.sleep(5) subsystem.poweroff() # power on and reset controller time.sleep(5) start = time.time() subsystem.poweron() nvme0.reset() logging.info(cmdlog_list)
cmdlog_error_only
这个参数可以指定上面的cmdlog_list只收集错误返回的命令信息。
ioworker返回值
调用ioworker的close()退出后,会得到这次ioworker的返回对象。返回对象包括如下数据:
- io_count_read:记录本次ioworker运行的时间内read命令的个数。
- io_count_nonread:记录本次ioworker运行的时间内非read命令的个数。
- mseconds:本次ioworker运行的时间,以毫秒(ms)为单位。
- latency_max_us:记录最大的IO命令的延迟,以微秒(us)为单位。
- error:当ioworker中有IO发生错误时,记录具体的错误代码。
- error_cmd和error_cpl:当ioworker中有IO发生错误时,记录具体发生错误的IO的SQE和CQE。
- cpu_usage:记录cpu的使用率,可以用来判断本次测试压力是否到达主机端的瓶颈。
- latency_average_us:记录所有IO命令的平均延时,以微秒(us)为单位。
- latency_distribution:只有当配置了output_percentile_latency参数时,会通过这个参数返回0-1000000us每个latency时间点的计数。
- latency_distribution记录了0-1秒中,每个毫秒延迟时间点上的IO个数。
- io_count_write:记录本次ioworker运行的时间内write命令的个数。
下面是一个正常结束的ioworker的返回对象:
'io_count_read': 10266880, 'io_count_nonread': 0, 'mseconds': 10001, 'latency_max_us': 296, 'error': 0, 'error_cmd': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'error_cpl': [0, 0, 0, 0], 'cpu_usage': 0.8465153484651535, 'latency_average_us': 60, 'test_start_sec': 1669363788, 'test_start_nsec': 314956299, 'latency_distribution': None, 'io_count_write': 0
这个是ioworker发生IO错误后的返回对象:
'io_count_read': 163, 'io_count_nonread': 0, 'mseconds': 2, 'latency_max_us': 791, 'error': 641, 'error_cmd': [3735554, 1, 0, 0, 0, 0, 400643072, 4, 0, 0, 5, 0, 0, 0, 0, 0], 'error_cpl': [0, 0, 131121, 3305242681], 'cpu_usage': 0.0, 'latency_average_us': 304, 'test_start_sec': 1669364412, 'test_start_nsec': 822867651, 'latency_distribution': None, 'io_count_write': 0
常见测试场景
4K全盘顺序读:
def test_ioworker_full_disk(nvme0n1): ns_size = nvme0n1.id_data(7, 0) nvme0n1.ioworker(lba_random=False, io_size=8, read_percentage=100, time=100).start().close()
4K全盘随机写:
def test_ioworker_qpair(nvme0n1): nvme0n1.ioworker(lba_random=True, io_size=8, read_percentage=0, time=3600).start().close()
在IO过程中中发起reset:
def test_reset_controller_reset_ioworker(nvme0, nvme0n1): # issue controller reset while ioworker is running with nvme0n1.ioworker(io_size=8, time=10): time.sleep(5) nvme0.reset()
metamode IO
PyNVMe3为SSD产品测试提供了高性能的NVMe驱动程序。但高性能也会导致缺乏灵活性,不能测试NVMe规范中定义的每一个细节。为了覆盖更多细节,PyNVMe3提供了metamode方式收发IO。
通过metamode方式,脚本可以直接创建并读写IOSQ/IOCQ,可以填写SQE和获取CQE中的每一个字段。
使用metamode需要脚本开发工程师对NVMe规范有一定的了解,反过来,metamode也可以帮助大家更好的理解NVMe的工作过程。
下面会通过一个简单例子帮助大家使用metamode方式写测试脚本。
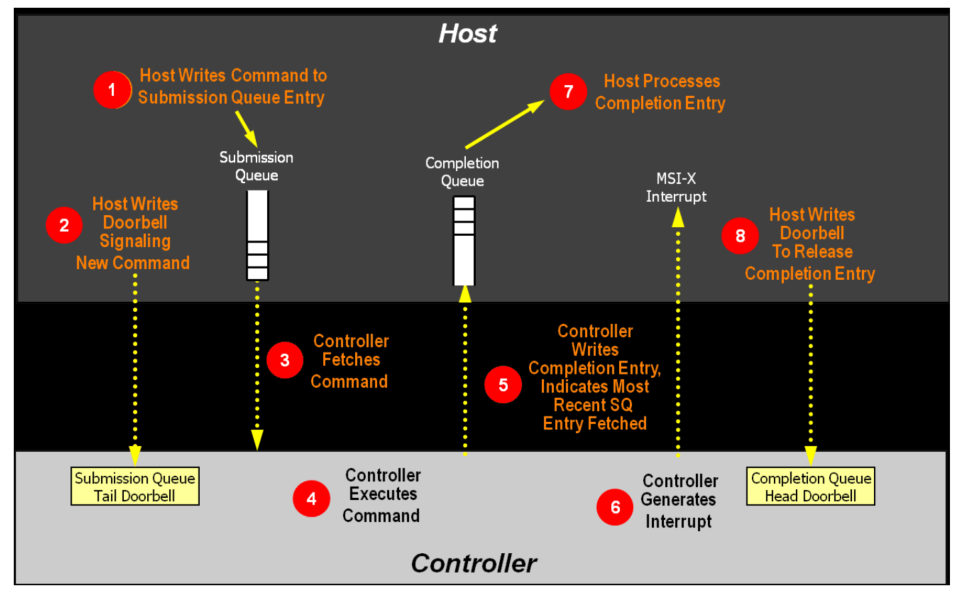
Step1. 主机将命令写入SQ Entry
cmd_read = SQE(2, 1) cmd_read.cid = 0 buf = PRP(4096) cmd_read.prp1 = buf sq[0] = cmd_read
Step2. 主机更新SQ tail doorbell寄存器。通知SSD有新的命令待处理。
sq.tail = 1
Step3. 盘从IOSQ获取SQE
Step4. 盘处理SQE
Step5. 盘向IOCQ写入CQE
Step6. 盘发出中断(可选)
step3-6由盘负责处理。
Step7. 主机通过观察p-bit发现并处理新的CQE。
cq.wait_pbit(cq.head, 1)
Step8. 主机写CQ head doorbell释放CQE
cq.head = 1
完整的测试脚本如下:
def test_matamode_read_command(nvme0): # 创建一个堆队列深度为10,QID为1的IOCQ SQ cq = IOCQ(nvme0, 1, 10, PRP(10*16)) sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq) # Step1. 主机将命令写入SQ Entry # 构造一个命令, opcode为2 (read command), namespace id为1, command id为0 cmd_read = SQE(2, 1) cmd_read.cid = 0 # 为命令设置PRP1,指向一段4k物理连续的内存区域 buf = PRP(4096) cmd_read.prp1 = buf # 将命令放入SQ的第一个entry中 sq[0] = cmd_read # Step2. 主机去更新SQ tail doorbell寄存器。通知SSD有新的命令待处理 # 更新SQ Tail doorbell为1 sq.tail = 1 # Step7. 主机处理Completion entry # 等待CQ中cq head指向的entry中的Phase Tag变成1 cq.wait_pbit(cq.head, 1) # Step8. 主机写CQ head doorbell释放completion entry # 更新CQ Head doorbell为1 cq.head = 1 # 获取CQ中第一个entry表示的命令完成整体和command id logging.info(cq[0].status)
上述脚本比较复杂,但可以控制测试的每一个细节。metamode也封装了read/write接口,方便脚本在metamode模式下发送常见的IO。以下测试脚本与上面例子实现相同的IO过程。
def test_metamode_example(nvme0): # 创建一个堆队列深度为10,QID为1的IOCQ SQ cq = IOCQ(nvme0, 1, 10, PRP(10*16)) sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq) # Step1. 主机将命令写入SQ Entry sq.read(cid=0, nsid=1, lba=0, lba_count=1, prp1=PRP(4096)) # Step2. 主机去更新SQ tail doorbell寄存器。通知SSD有新的命令待处理。 sq.tail = 1 # Step7. 主机处理Completion entry cq.waitdone(1) # Step8. 主机写CQ head doorbell释放completion entry cq.head = 1 # 获取CQ中第一个entry表示的命令完成整体和command id logging.info(cq[0].status)
metamode除了可以设定主机处理命令的流程,也可以对命令中具体的参数进行配置。下面将例举几种场景,帮助大家更好的了解metamode。
构造自定义的PRP List
def test_prp_valid_offset_in_prplist(nvme0): # 创建一个堆队列深度为10,QID为1的IOCQ SQ cq = IOCQ(nvme0, 1, 10, PRP(10*16)) sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq) # 构造PRP1,设定offset为0x10 buf = PRP(ptype=32, pvalue=0xffffffff) buf.offset = 0x10 buf.size -= 0x10 # 构造PRP list,设定offset为0x20 prp_list = PRPList() prp_list.offset = 0x20 prp_list.size -= 0x20 # 填充8个PRP entries放到PRP list for i in range(8): prp_list[i] = PRP(ptype=32, pvalue=0xffffffff) # 用上面的PRP和PRP list构造一个read命令 cmd = SQE(2, 1) cmd.prp1 = buf cmd.prp2 = prp_list # 设定命令的cdw12为1 cmd[12] = 1 # 将命令写入SQ Entry,更新SQ tail doorbell sq[0] = cmd sq.tail = 1 # 等待CQ pbit翻转 cq.wait_pbit(0, 1) # 更新CQ head doorbell cq.head = 1
多个SQ映射到同一个CQ
def test_multi_sq_and_single_cq(nvme0): # 创建多个队列深度为10,QID为1的IOCQ SQ cq = IOCQ(nvme0, 1, 10, PRP(10*16)) sq1 = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq) sq2 = IOSQ(nvme0, 2, 10, PRP(10*64), cq=cq) sq3 = IOSQ(nvme0, 3, 10, PRP(10*64), cq=cq) # 构造一个命令, opcode为1 (write command), namespace id为1, command id为1 cmd_write = SQE(1, 1) cmd_write.cid = 1 # FUA bit 置 1 cmd_write[12] = 1<<30 # 为命令设置PRP1,指向一段4k物理连续的内存区域 buf2 = PRP(4096) buf2[10:21] = b'hello world' cmd_write.prp1 = buf2 # 构造一个命令, opcode为2 (read command), namespace id为1, command id为2 cmd_read1 = SQE(2, 1) buf1 = PRP(4096) cmd_read1.prp1 = buf1 cmd_read1.cid = 2 # 构造一个命令, opcode为2 (read command), namespace id为1, command id为3 cmd_read2 = SQE(2, 1) buf3 = PRP(4096) cmd_read2.prp1 = buf3 cmd_read2.cid = 3 # 将命令放入Step1中的SQ的第一个entry中 sq1[0] = cmd_write sq2[0] = cmd_read1 sq3[0] = cmd_read2 # 更新SQ1 Tail doorbell为1 sq1.tail = 1 # 等待CQ中cq head指向的entry中的Phase Tag变成1 cq.wait_pbit(cq.head, 1) # 更新CQ Head doorbell为1 cq.head = 1 # 更新SQ2 Tail doorbell为1 sq2.tail = 1 cq.wait_pbit(cq.head, 1) # 更新CQ Head doorbell为2 cq.head = 2 # 更新SQ3 Tail doorbell为1 sq3.tail = 1 cq.wait_pbit(cq.head, 1) # 更新CQ Head doorbell为3 cq.head = 3 # 获取CQ中第一个entry表示的命令完成整体和command id logging.info(cq[0].status) logging.info(cq[0].cid)
构造两个命令使用相同的command id
def test_same_cid(nvme0): # 创建一个堆队列深度为10,QID为1的IOCQ SQ cq = IOCQ(nvme0, 1, 10, PRP(10*16)) sq = IOSQ(nvme0, 1, 10, PRP(10*64), cq=cq) # 将两个command id同为1的命令写入SQ cmd_read1 = SQE(2, 1) buf1 = PRP(4096) cmd_read1.prp1 = buf1 cmd_read1.cid = 1 cmd_read2 = SQE(2, 1) buf2 = PRP(4096) cmd_read2.prp1 = buf2 cmd_read2.cid = 1 # 更新SQ tail doorbell sq.tail = 2 # 等待CQ中entry 1中的Phase Tag变成1 cq.wait_pbit(1, 1) # 更新CQ Head doorbell为1 cq.head = 2 # 获取CQ中第2个entry表示的命令完成状态和command id logging.info(cq[1].status) logging.info(cq[1].cid)
构造invalid doorbell错误
def test_aer_doorbell_out_of_range(nvme0, buf): # 发送一个AER命令 nvme0.aer() # 创建一对CQ和SQ,队列深度为16 cq = IOCQ(nvme0, 4, 16, PRP(16*16)) sq = IOSQ(nvme0, 4, 16, PRP(16*64), cq.id) # 更新SQ tail doorbell为20,超出SQ的队列深度,是invalid doorbell with pytest.warns(UserWarning, match="AER notification is triggered: 0x10100"): sq.tail = 20 time.sleep(0.1) nvme0.getfeatures(7).waitdone() # 发送get logpage命令清除异步事件 nvme0.getlogpage(1, buf, 512).waitdone() #删除SQ和CQ sq.delete() cq.delete()
通过metamode方式发送IO,脚本可以直接读写NVMe协议定义的各种元数据结构,包括:IOSQ,IOCQ,SQE,CQE,doorbell,PRP,PRPList,以及各种SGL。脚本读写的这些数据会直接被NVMe盘获取,IO路径上没有使用任何操作系统或者驱动程序,因此也不会受到任何限制。
总结
PyNVMe3是一个面向NVMe固态硬盘开发和测试人员的脚本开发库,包括了一个高性能的用户态NVMe驱动,以及一个可扩展的Python API接口。通过这个Python接口,用户可以利用Python社区的所有工具,来提高测试脚本的开发能力和效率。PyNVMe3推出后,得到很多SSD厂商以及OEM厂商的支持,在广大客户的帮助下,PyNVMe3得到了更多打磨和实战的机会,获得了很大的成长。在此感谢所有用户的使用和反馈!也希望这份文档可以帮助大家更进一步了解PyNVMe3测试脚本的开发,帮助我们一起测好SSD!